
What is the best URL structure for SEO and users?
It stands for Uniform Resource Locator and essentially we can think of it as the zip code of our digital home, the unique and unambiguous address that allows our site to be found among the billions of others that populate the Web. The URL is thus a fundamental element for navigation and orientation in the Web universe, but it is also a real signal we send to search engines and visitors to our site. Even a seemingly simple and technical element such as the Web address, which essentially serves to inform of the location of a resource such as a specific site, page or file within the Web, can therefore play a role in site optimization, which is why we must try to understand what is meant by and what SEO friendly URLs are. Necessary preamble: we should not imagine particularly sensitive impacts in terms of ranking from choosing one of several options for managing URLs and setting up an effective address structure for our content from an SEO perspective,but there are nonetheless potential effects on the experience provided to users.
What is a URL: full address of a site
Let’s start with the definition of URL, which as mentioned is an acronym for Uniform Resource Locator.
From a practical point of view, URL is a unique address that distinctly and uniquely identifies a specific resource on the Internet, such as a web page, an image or a file, functioning similarly to the full address of a house, allowing it to be found among all the others.
The standard structure that can be used to set this address was codified by Internet daddy Tim Berners-Lee in IETF document RFC 3986, which defines URL as the sequence the characters that uniquely identifies any online resource, such as a page, image or file, and which by extension also identifies the file structure of any site, representing in this sense the full address of a site.
What is the standard structure of URLs
There are essentially eight parts of which each URL is composed, between mandatory and optional elements, and each has a specific meaning.
Starting from the left, the first portion is the schema, which indicates the protocol used to access the resource located on the servers. The current standard is http:// or https://, but there can also be paths such as mailto: (which automatically routes to the e-mail client) or ftp: (to handle file transfers).
This is followed by the string :// which is a simple separator between the protocol and the remaining part of the URL, which is usually the host or, less frequently, the username. Until a few years ago, immediately following the protocol was the option of specifying authentication credentials for accessing the online resource: the username:password@ string, however, was gradually abandoned because it risked opening the way to phishing (credentials were sent in plain text to the server, without encryption, and the path could lead to pages other than those expected), and today that function is deactivated, although some browsers including Firefox keep it active, while still warning users of the potential dangers to which they are exposing themselves.
What the full address of a site looks like: URLs with characters, numbers and slugs
In the most common formulations, after protocol and :// is an indication of the domain name of the host, i.e., the address of the server on which the resource resides, which software automatically converts to an IP address by making use of the DNS service; in other cases, the numeric IP address may be displayed directly, but this solution is rarer.
Typically, the standard URL path stops at these parameters, but there are also four other optional elements that can be added to the Web address: the port (of the service to which the request is to be forwarded, usually omitted because standard ports associated with the protocol are referenced); the path (pathname) within the server’s file system to identify the requested resource; the query string, a string of characters, separated with a ? symbol, that allows one or more parameters to be transmitted to the server; and the fragment, which indicates a part or location within the resource.
The path part is also called the slug. Technically, this is the string that uniquely identifies a specific page or resource within a Web site. For example, in the URL https://www.example.com/blog/my-first-post, the slug is my-first-post, and it is a unique identifier that is used to refer to that specific resource. The term has its roots in journalism, where “slug” refers to a short string of words that identifies an article as it is being produced, and has since been adopted in the Web world. This is the variable part of a URL, the part over which we have the most control and over which we generally intervene to make it meaningful and user-friendly, so as to write a more attractive and clickable URL for users.
URL meaning: an address to provide relevant information
Each part of the URL provides important information to both site visitors and search engines. For example, the host field is like the street name in a physical address, while the path, which indicates the specific location of the resource within the site, is like the house number in a physical address.
It follows that a well-structured URL can help visitors understand where they are and what they are looking at, and it can help search engines understand what the page is about and how it should be indexed. It is as if we are giving directions to a friend who is visiting our house for the first time: a clear and precise address will help him find his way without any problems.
That is why it is said that a URL is not just an address, but a key element of our online presence.
URL SEO: why to take care of this aspect for site optimization
As we also said in our in-depth discussion on the 200 ranking factors, page address structuring can also have an influence on search engine rankings, and therefore you need to evaluate various aspects when reasoning about the standard to apply to the pages of your site.
The importance of URLs on ranking and user experience
Defining an effective URL path can have 3 positive effects for SEO: it impacts ranking, improves user experience, and is a potential anchor text for page sharing.
URL address and ranking on Google
With regard to ranking, leaving aside talk of a hypothetical direct relationship between URL optimization and Google rankings, there is, however, one element that should not be overlooked, that of better readability: the easier it is for Google to read and interpret the URL, the easier it will be to determine relevance and thus rankings for a search query.
In practical terms, then, it is believed that using Urls that contain keywords can be a system to improve the visibility of the site in searches, but one should not make the mistake of making useless paths just to put keywords in the string.
The relationship between URLs and UX
Similar is the talk about user experience, because a well-structured URL provides both search engines and humans with easy-to-understand indications about the content of the landing page, and for this reason it is preferable to make a human-readable and semantically accurate URL that gives a clear idea of the topic of the page and what the visitor who clicks on the link is expecting.
The URL as anchor text
Finally, a well-written URL can be more easily copied and pasted as a link in forums, blogs, social media networks, or other contexts, becoming an ideal anchor text.
What Talking URLs or SEO Friendly URLs are
URL structures that meet the parameters described above are precisely called SEO friendly or speaking URLs: this definition covers all addresses that clearly describe in real words the actual content of the referring page, allowing the user (and the search engine) to immediately know what kind of information to expect.
For a site’s SEO, a talking URL can:
- greatly facilitate user search.
- help give it greater ranking weight in Google’s SERPs
- optimize page traffic, driving increased visibility and click-through rates.
Tips for managing speaking URLs
To be effective, speaking URLs should always be short, but descriptive; we can use keywords identified as central to the topic or otherwise terms that refer specifically to the content of the page and that are clear and easy to understand.
The goal is to have a concise address-the recommended length by best practices is between 50 and 60 characters, avoiding exceeding 115 characters to avoid problems-clear and relevant, which can serve the user to immediately understand its correlation with the content they are interested in.
Again, our reference should be the user even before the search engine, trying to ensure easy accessibility and a good experience for those who discover the site among the results of a Google search. In fact, it is believed that a URL composed in a way that is very distant from the on-page content or loaded with unreadable parameters and characters can worsen the bounce rate and discourage readers from staying on the pages.
SEO best practices for URLs
So here we outline some SEO best practices for URL management:
- Keep addresses as simple, relevant, compelling and curated as possible-this is the key to convincing both users and search engines.
- Although, as mentioned, numbers and ID codes can be included in URLs, the best practice is to use words that people can understand, using semantically correct, user-readable paths.
- URLs should be definitive but concise: simply by reading the URL a user and a search engine should understand what to expect on the page.
- To facilitate readability use hyphens to separate words. It is recommended to avoid underscores, spaces or other characters to separate words: however, if all Urls on a site have underscores, it is not recommended to change them in progress.
- URLs are case sensitive, so it is best to use lowercase letters because in some cases uppercase letters can cause problems with duplicate pages (or in any case it is better to use a consistent line).
- If possible, avoid using URL parameters, which can create problems with tracking and duplicate content. In any case, even when it is not possible to do without them, it is good to use URL parameters sparingly.
URLs and SEO: best practices according to Google
Within Google’s SEO guidelines there is a chapter dedicated to the most correct handling of web addresses, which gives some examples of recommended practices and potential mistakes in URL creation, also suggesting methods to solve the most common problems.
This guide, updated in English at the end of July 2023, first specifies which characters Google Search supports in URLs, clarifying that “Google supports URLs as defined by RFC 3986.” In addition, characters defined by the standard as reserved must be percentage-encoded; non-reserved ASCII characters can be left in the unencoded form, while, characters in the non-ASCII range must be encoded in UTF-8.
Also as a rough guideline, then, Google urges, whenever possible, to use readable words rather than long ID numbers in URLs.
On the practical side, these are some of the specific cases analyzed by the paper:
- Recommended forms
- Simple, descriptive words in the URL – https://en.wikipedia.org/wiki/Aviation
- Localized words in the URL, if applicable – https://www.example.com/lebensmittel/pfefferminz
- Use of UTF-8 encoding as needed.

In the examples in the image above, we see respectively the use of UTF-8 encoding for Arabic characters, for Chinese characters, for umlaut (the two dots above vowels found in some languages, such as German, and which technically are a diacritical mark indicating a variation in the pronunciation of that vowel), and for emoji in the URL.
Again, if the site is multi-regional it might be best to use a URL structure that simplifies geographic targeting, and in particular the use of:
- Country-specific domain – https://example.de
- Country-specific subdirectory with gTLD – https://example.com/de/
In addition, Google suggests preferring the use of hyphens instead of underscores to separate words in URLs, which allows users and search engines to more easily identify the concepts contained in the URL.
- Use of hyphens (-) – https://www.example.com/summer-clothing/filter?color-profile=dark-grey
- Forms that are not recommended
- Use of non-ASCII characters in the URL, as in the image below (which is basically the opposite choice from those suggested above)
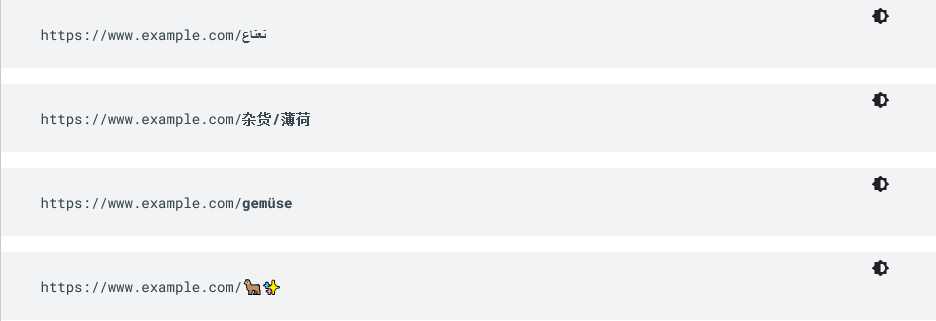
- Long, unreadable ID numbers in URL – https://www.example.com/index.php?id_sezione=360&sid=3a5ebc944f41daa6f849f730f1
- Use of underscores, underscores (_) – https://www.example.com/summer_clothing/filter?color_profile=dark_grey
- Use of merged words in URLs – https://www.example.com/greendress
Common problems for handling URLs
The support resource also looks at some common critical situations we can encounter when managing our site’s addresses.
In particular, Google points out how extremely complex URLs, and especially those containing multiple parameters, can cause problems for crawlers by creating unnecessarily large numbers of URLs pointing to identical or similar content on the site. As a result, Googlebot may use much more bandwidth than necessary or not be able to fully index all the content on the site-in short, problems even with the crawl budget.
This unwarranted excess of URLs can be caused by a number of problems, including:
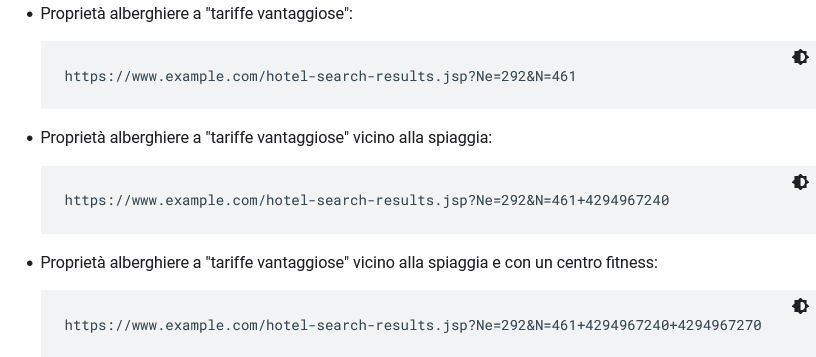
- Additional filters of a set of items. Many sites provide different views of the same set of items or search results, such as when they allow the user to filter this set using defined criteria (e.g., show me hotels on the beach). When filters can be combined by addition (e.g., hotels on the beach and with a fitness center), the number of URLs (data visualizations) across sites increases dramatically. Creating a large number of hotel listings with slight differences is redundant, because Googlebot needs to see only a few listings to reach each hotel page, as in the examples in the image.
- Dynamic document generation: this operation may result in slight changes, due to counters, timestamps or presence of advertisements.
- Problematic parameters in the URL: session IDs, for example, can create huge amounts of duplicates and a very large number of URLs.
- Sorting parameters: some large shopping sites provide multiple ways of sorting the same items, resulting in a large increase in the number of URLs.
- Irrelevant parameters in the URL, e.g., referral parameters.
- Calendar issues: A dynamically generated calendar can create links to past and future dates without restrictions on start and end dates.
- Inaccessible relative links: inaccessible and broken relative links are often the cause of infinite space. This problem occurs especially when there are repeated path elements.
How to solve the main problems with URLs
Also in light of the situations just described, the guide concludes with a number of practical tips to avoid potential problems related to URL structure.
- Create a simple URL structure. In principle, the ideal solution would be to organize content in such a way that URLs are constructed logically and in the way most understandable to humans.
- Use a robots.txt file to block Googlebot access to problematic URLs. Consider especially blocking dynamic URLs, such as URLs that generate search results or URLs that can create infinite space, such as calendars; using regular expressions in the robots.txt file can allow us to easily block a large number of URLs.
- Where possible, do not use session IDs in URLs, replacing them with cookies.
- If the web server is not case sensitive–and therefore treats upper and lower case text in a URL the same way–you should convert all text to the same format so that it is easier for Google to determine that the URLs refer to the same page.
- Reduce the length of URLs if possible by removing unnecessary parameters.
- If the site includes an infinite calendar, add a nofollow attribute to links pointing to future dynamically created calendar pages.
- Check for inaccessible relative links on the site.
URLs and SEO, Google’s advice on maximum length
The ideal URL length for SEO is an issue that has often been the focus of debate in the international community, prompting Google – and Search Advocate John Mueller in particular – to step in several times to offer clarifications and explanations on what is considered SEO friendly for the search engine.
The general advice is that even if URL management offers no direct effect in terms of ranking, it still has an impact on the type of experience provided to users, both in a good way and in a pejorative way: therefore, if we are considering options for managing the addresses of our content from an SEO perspective, it is advisable to pay (albeit minimal) attention to the actual length of the URLs, trying to avoid some mistakes that can prove harmful.
The revelation that comes from the Googler during a YouTube hangout is very clear, and then reiterated further in an appointment with #AskGooglebot: according to John Mueller, the ideal URL should never exceed 1,000 characters, although “I guess you have to work hard to create addresses that long,” he ironizes.
Never exceed 1,000 characters in URLs
Google’s advice is simple: although Web browsers can handle lengths up to a maximum of two thousand characters, a site’s URLs should be short and never exceed the 1,000-character threshold. It is clear that a more concise address tends to be preferable, partly for issues of shareability and readability by human users, but for search engines there is no problem as long as the four digits.
Google does not have a preferred solution for URL structure
This good practice applies to all types of URLs, Mueller further explains, “some sites use parameters, some use folders with filenames, each handles Urls slightly differently,” but in general there is no ideal or preferred solution for the search engine, the Googler reveals.
More specifically, Google uses “URLs as identifiers and it doesn’t matter how long they are” or the number of slashes in the address: the advice is to keep them shorter than 1,000 characters, “but that’s just to make tracking easier.”
Thus, the length of a URL does not affect ranking and may only affect the appearance of search snippets.
Pay attention to canonicalization
There is only one part of Google’s systems where URL length plays a role: canonicalization, which is what happens when the search engine finds multiple copies of a page on the same website and has to choose a URL to use for indexing. As Mueller explains in a later appointment with #AskGooglebot, if Google finds “a shorter, cleaner URL, our systems tend to select that” over a longer, more complex address.
This is not something that affects page ranking, but “it’s purely a matter of which URL is shown in Search,” he further clarifies.
SEO needs readable, scannable URLs
Ultimately, what is needed for SEO and site usability is for Google to be able to “take that URL you have, scan it, collect the present on that address, and index it.”
URL length doesn’t make a difference for SEO, then, and how you “determine which URL to use is up to you,” personal evaluations, site type, and so on: all Google needs is for the character string to be readable, interpretable by Googlebot, and refer to an indexable resource.
All other matters are left to the site owner, webmaster and possibly the SEO consultants working on it!
SEO friendly URLs: better absolute or relative?
Another issue that often causes Hamletian doubts to SEO is that of absolute versus relative URLs, which gives rise to opinions are more divided between those who promote the adoption of one structure versus those who emphasize the benefits of the other.
John Mueller also talked about this within another #AskGooglebot pill on YouTube, with an episode focused precisely on clarifying the differences between absolute and relative URLs and whether there is a preference in the way a search engine crawls and indexes these addresses.
What absolute URLs and relative URLs mean
As mentioned, URLs are the basis of all Web sites and represent in a standard way the location of a generic resource that a user can access; the location of a Web page can be done by providing an absolute or relative URL address.
The absolute URL is a complete address, which includes all the data needed to access that page, file or resource – protocol, server, absolute path and document name: as Mueller says, it is equivalent to “providing someone with the complete address of a place they are trying to reach.”
The relative URL is a partial address, relating precisely to where the user is at that moment on the site, and they associate the code with the current directory structure or file. Taking the example of directions, the Googler explains that it is like telling a person “go to the greenhouse straight down the street.”
The differences between absolute and relative URLs
Even more precisely, also following the guidance in this Microsoft guide, an absolute URL uses the format < schema://server/path/resource >, while “a relative URL locates a resource using an absolute URL as a starting point,” in that the full URL of the destination “is specified by concatenating the absolute and relative URLs.”
The relative URL usually consists only of the path and, optionally, the resource, while the schema and server are absent. In practice, with relative addresses everything seems to be missing except the filename, and the browser understands that to complete the URL and actually reach the page it must use the path to the current folder.
It may be helpful at this point to clarify the terminology of the URL:
- Schema, which specifies how the resource is accessed.
- Server, part that specifies the name of the computer where the resource is located.
- Path, specifies the sequence of directories leading to the destination. If resource/resource is omitted, the destination is the last directory in the path.
- Resource, is the destination, usually the name of a file. This can be a simple file, containing a single binary byte stream, or a structured document, containing one or more archives and binary byte streams.
Absolute or relative URLs: which is the best choice for the site
In practical terms, setting an absolute URL or a relative URL obviously generates a difference for the site.
In the former case, the address contains more information and refers precisely to a unique location and a unique file; moreover, the use of absolute URLs is mandatory for outbound links to other sites, which thus have a different domain name, because otherwise they cannot be correctly detected by the browser.
The problem with absolute URLs arises in the case of any site migration or relocation, because if we move the site to another server or domain, we necessarily have to rewrite all the addresses to enable resources to be reached effectively.
It is (also) for this reason that, usually, relative URLs, which are shorter and more portable, are considered more valuable and convenient-even if, as pointed out, they serve only to refer to links that reside on the same server as the current page. Indeed, in the case of migration, it will not be necessary to rewrite all page URLs or to correct internal links between pages on the site, because these resources will always function properly regardless of their location, without misdirection.
Moreover, relative addresses are also recommended for sites organized in directories, because they make it easier to manage the multitude of pages registered and grouped in multiple folders, as they provide only the information strictly necessary to find the pages within the site.
Which option to choose for SEO
The difference between absolute URL and relative URL thus has a technical and practical explanation; but what is Google’s position, and thus what is the best choice for SEO?
According to John Mueller, there is actually no preferred or perfect solution because, “when implemented correctly, both of these approaches lead to exactly the same position” and therefore for Google Search “it doesn’t matter at all which one you use on your site.”

In terms of optimization and ranking, therefore, “Google treats both exactly the same,” and indeed we can “even use both types of URLs within the same website, because there is absolutely no relative difference.”
What matters to Search and, more generally, to search engines is having a unique URL per content element, which then allows them to crawl and index that content in a way that presents it to users, but how we secure this requirement is up to us.
URLs and SEO, changing structure is not a recommended solution
Speaking of SEO friendly URLs, there is one more piece of advice coming from Mountain View that should be put into practice by those doing technical SEO on the site: setting up an effective URL structure at the outset is undoubtedly a key to avoiding changes down the road that can compromise the user experience and the site’s search engine results, so let’s go over what that means and how to achieve it.
The value of URLs for SEO and site usability
For SEO and site usability, there are certain standards to be met with respect to URLs, as mentioned, starting with the criteria of readability, ability to make the address interpretable by Googlebot, and referral to an equally accessible resource for search engine indexing.
Changing URL structure? A choice to be carefully considered
That being said, there are situations in which one can consider transforming the structure used for URLs and opting for a more SEO-friendly solution (at least in appearance): technically, one can proceed with a site URL migration intervention, which is especially useful when there are problems and is performed with rewriting rules.
The advice is to avoid site address overturns
As a general rule, however, one should try to avoid resorting to these techniques because there are so many mistakes that can compromise the health of the project, and above all, one should always do them by relying on experienced professionals because losing or leaving something behind in the URL structure renewal phase can cost rankings and traffic to the site.
When URL changes are unavoidable
So, it is a case of carefully weighing the situation and asking yourself why you are thinking of changing site URLs. There are times when such a change is unavoidable: among the most common reasons are rebranding, site migration or deep redesign of the site and some basic elements (the domain name, product types, topic focus), CMS platform changes that no longer allow the same addresses to be kept, or presence of problems such as outdated dates in addresses, unnecessary elements, moving entire directories.
The consequences for usability
However, according to experts in other less urgent circumstances it would always be better to avoid changing the URL structure, even regardless of SEO reasoning. Just to give examples, a change might stop working the bookmarks that users have saved in their browsers from visiting the site or from previous email marketing campaigns or newsletters: any disruption of the URL structure removes the direct relationship that the user has with a site.
No less complex is the handling of 301 redirects: if the site has undergone a complete overhaul, there may be no direct page to redirect the user to, and so in the process you risk losing that traffic (and previously gained ranking).
The SEO dangers of URL twisting
And so we come to the SEO-related dangers that these changes can cause (and therefore should invite at least some long thought before launching into the operation): the main ones are the management of links and previous backlinks received and the time it takes Google to rediscover the site’s pages through the new URLs.
Risk of losing backlinks
Regarding the first point, we know that links are still one of the main ranking factors and that the quality and quantity of links are a signal and one of the measures by which Google estimates the potential relevance and reliability of a site. In this process, therefore, one should not forget all the external links to the Web site, which one should try to modify and update: an operation that is not always possible and not always easy, because it may be necessary to contact the various webmasters to ask for changes to the addresses. More generally, then, one should also change paid campaigns, social platforms, and off-site advertising.
Taking good care of internal links
When carrying out a site redesign, there is a risk of neglecting then internal links, thus reducing the SEO value of the new design: it is therefore crucial to create a “before and after” sitemap, making sure to redirect pages to be abandoned (but still useful for traffic as well) via a permanent 301 to a new page that matches the previous one in terms of topic.
On the other hand, if you redirect to a page with content that is not similar to the previous one, you may lose PageRank, because Google may remove the value of such links. Similarly, you should never redirect all pages to the home page or to a top-level page, because those backlinks could be devalued as irrelevant.
Google needs time to rediscover new URLs
The other problematic front concerns the time it takes Google to properly rediscover and process the new URLs on the site, and during this period it is possible to experience a drop in rankings and thus in organic traffic. Of course, this is a contingency and a temporary situation (if you perform the migration process correctly), but nonetheless it is a factor to take into account when considering whether you should change your Url structure. For this reason, it might be useful to plan these actions during the least busy time of the year and to follow all the appropriate protocols to avoid mistakes.
John Mueller’s advice: don’t change URLs if you don’t have to
In conclusion, let’s remember what our dear John Mueller says (in a comment on reddit) about changing URL structure, because it sums up everything we have written so far:
“I’d avoid changing URLs unless you have a really good reason to do so, and you’re sure that they’ll remain like that in the long run.”