
URL: che cos’├©, cosa significa e a cosa serve
È l’indirizzo completo di un sito, una stringa di testo che assume un significato cruciale per la navigazione su Internet perché rende l’accesso alle risorse web ordinato e organizzato. Parliamo di URL, acronimo di Uniform Resource Locator, che possiamo definire il codice postale della nostra casa digitale, l’indirizzo unico e univoco che consente al nostro sito di essere trovato in mezzo ai miliardi di altri che popolano la Rete. Oltre a essere un elemento fondamentale per l’orientamento nell’universo del web, è anche un vero e proprio segnale che inviamo ai motori di ricerca e ai visitatori del nostro sito, e può svolgere un ruolo nell’ottimizzazione del sito. Cerchiamo insomma di capire cosa sono gli URL, come sono strutturati e perché sono così importanti per la SEO, e anche perché gli URL SEO friendly e ben progettati possono (ancora) fare la differenza tra un sito facilmente trovabile e uno che rimane nascosto nei meandri del web.
Che cos’è un URL
URL è un acronimo di Uniform Resource Locator, che in italiano significa localizzatore uniforme di risorse.

In termini semplici, un URL è l’indirizzo completo di un sito web o di una risorsa specifica su Internet. Dal punto di vista pratico, quindi, è l’elemento che identifica in modo distinto, univoco e preciso una risorsa specifica su Internet, come una pagina web, un’immagine, un video, un file o qualsiasi altro contenuto disponibile online, funzionando in maniera simile all’indirizzo completo di una casa, che permette di trovarla tra tutte le altre.
Ma cosa significa esattamente URL? È la stringa di testo che inseriamo nella barra degli indirizzi del browser per raggiungere una determinata pagina web e rappresenta uno degli elementi fondamentali del web, essenziale per la navigazione e l’accesso alle risorse online.
Significato e definizione di URL
Il concetto di URL è stato introdotto per la prima volta da Tim Berners-Lee, il padre del World Wide Web, come parte del progetto per creare un sistema di identificazione univoco per le risorse online.
Nel documento RFC 3986 della IETF si definisce URL la sequenza i caratteri che identifica in modo unico e univoco una qualsiasi risorsa online, come una pagina, un’immagine o un file, e che per estensione identifica anche la struttura dei file di un qualsiasi sito, rappresentando in tal senso l’indirizzo completo di un sito.
L’acronimo URL è quindi un termine tecnico è utilizzato per descrivere l’indirizzo che permette di localizzare una risorsa specifica su Internet in modo univoco. In particolare, la parola “Uniform” indica che il formato degli URL è standardizzato, il che significa che tutti gli URL seguono una struttura comune, rendendo più facile per i browser e i motori di ricerca interpretare e accedere alle risorse.
A cosa servono gli URL
Come detto, un Uniform Resource Locator è essenziale per la navigazione e l’accesso alle risorse su Internet. Nella sua essenza, serve come indirizzo univoco che permette di localizzare e accedere a specifiche pagine web, immagini, video, documenti e altre risorse online. Senza URL, sarebbe impossibile per gli utenti e i motori di ricerca trovare e accedere alle informazioni disponibili sul web.
Gli URL svolgono anche altre funzioni chiave. Prima di tutto, facilitano la navigazione, permettendo agli utenti di spostarsi facilmente tra diverse pagine e siti web. Ad esempio, inserendo un URL nella barra degli indirizzi del browser, possiamo accedere direttamente a una pagina specifica senza dover passare attraverso una serie di link intermedi.
Inoltre, gli URL sono fondamentali per la SEO: i motori di ricerca utilizzano gli URL per indicizzare e classificare le pagine web. Un URL ben strutturato e contenente parole chiave rilevanti può migliorare il posizionamento di una pagina nei risultati di ricerca, rendendola più visibile agli utenti.
Gli URL sono anche cruciali per la condivisione di contenuti. Possiamo copiare e incollare un URL in un’email, un messaggio di testo, un post sui social media o un documento per condividere facilmente una risorsa con altri utenti. Questo rende gli URL strumenti potenti per la diffusione di informazioni e la promozione di contenuti online.
Infine, gli URL sono utilizzati per la gestione e l’organizzazione dei contenuti all’interno di un sito web. Permettono di creare una struttura logica e coerente, facilitando la navigazione interna e migliorando l’esperienza dell’utente. Ad esempio, un URL come https://www.esempio.com/blog/guida-seo non solo indica chiaramente il contenuto della pagina, ma aiuta anche a organizzare il sito in modo intuitivo e accessibile.
Cosa vuol dire inserire URL?
Proseguendo nelle spiegazioni basic, inserire un URL significa aggiungere un indirizzo web all’interno di un contenuto digitale, come una pagina web, un documento, un’email o un post sui social media, per creare un collegamento ipertestuale che permette agli utenti di accedere direttamente a una risorsa specifica su Internet. Questo processo è fondamentale per la navigazione online, poiché consente di collegare diverse pagine e risorse, facilitando l’accesso alle informazioni e migliorando l’esperienza dell’utente. Ad esempio, inserire un URL in un articolo di blog permette ai lettori di cliccare sul link e visitare una pagina correlata per ulteriori dettagli o approfondimenti.
Come si inserisce l’URL?
Inserire un URL è un’operazione semplice, che varia a seconda del contesto in cui ci troviamo.
Se stiamo lavorando su una pagina web, possiamo utilizzare il codice HTML per creare un collegamento ipertestuale. Ad esempio, il codice <a href=”https://www.esempio.com”>Visita il nostro sito</a> crea un link che, quando cliccato, porta l’utente al sito specificato. Nei sistemi di gestione dei contenuti (CMS) come WordPress, possiamo inserire un URL utilizzando l’editor visuale: selezioniamo il testo che vogliamo trasformare in link, clicchiamo sull’icona del link e inseriamo l’URL nel campo apposito. In un’email, possiamo semplicemente copiare e incollare l’URL nel corpo del messaggio o utilizzare le opzioni di formattazione per creare un link cliccabile.
Anche sui social media possiamo inserire un URL direttamente nel post o nel campo apposito per i link, permettendo agli utenti di cliccare e visitare la risorsa collegata. Ad esempio, su piattaforme come Facebook o X possiamo incollare l’URL direttamente nel campo di testo del post, e il sistema genererà automaticamente un’anteprima del link, rendendolo più attraente e cliccabile per gli utenti.
In tutti questi casi, l’obiettivo è rendere il link facilmente accessibile e visibile, migliorando così la navigazione e l’esperienza dell’utente.
Struttura degli URL, la chiave per orientarsi nel Web
La standardizzazione degli URL è stata cruciale per lo sviluppo del web, poiché ha permesso di creare un sistema coerente e affidabile per la navigazione online. Senza URL, come detto, sarebbe impossibile per gli utenti trovare e accedere alle risorse web in modo efficiente.
Inoltre, come vedremo più approfonditamente, un URL ben strutturato e ottimizzato può migliorare significativamente la visibilità di un sito nei risultati di ricerca, perché resta ancora oggi un elemento a cui Google dedica attenzione per le sue valutazioni.
Anche la struttura standard che si può utilizzare per impostare questo indirizzo è stata codificata dal papà di Internet Tim Berners-Lee. Ancora oggi, gli URL sono quindi composti da diverse parti, ognuna delle quali ha una funzione specifica.
Ad esempio, in un URL come https://www.esempio.com/percorso/pagina?parametro=valore, https è il protocollo, www.esempio.com è il dominio, /percorso/pagina è il percorso, e parametro=valore rappresenta i parametri di query. Ogni componente contribuisce a localizzare e accedere alla risorsa desiderata.
Come è strutturato un URL? Le componenti della struttura standard
Un URL è molto più di una semplice sequenza di caratteri: è una struttura complessa e ben definita che permette di localizzare e accedere a risorse specifiche su Internet.
Sono essenzialmente otto le parti di cui si compone ogni URL, tra elementi obbligatori e opzionali, e ognuna ha un significato specifico.
Partendo da sinistra, la prima porzione è rappresentata dallo schema, che indica il protocollo utilizzato per accedere alla risorsa localizzata sui server e quindi il metodo utilizzato per accedere alla risorsa. Lo standard attuale è http:// o https://, ma ci possono anche essere percorsi come mailto: (che indirizza in automatico al client di posta elettronica) o ftp: (per gestire il trasferimento di file).
Segue la stringa :// che è un semplice separatore tra il protocollo e la rimanente parte dell’URL, che in genere è l’host o, meno frequentemente, lo username. Fino a qualche anno fa, subito dopo il protocollo c’era la possibilità di specificare le credenziali di autenticazione per accedere alla risorsa online: la stringa username:password@ è stata però progressivamente abbandonata perché rischiava di aprire la strada al phishing (le credenziali erano inviate in chiaro al server, senza cifrature, e il percorso poteva condurre a pagine diverse da quelle attese), e oggi tale funzione è disattivata, anche se alcuni browser tra cui Firefox la mantengono attiva, segnalando comunque gli utenti dei potenziali pericoli cui si espongono.
Nelle formulazioni più comuni, dopo protocollo e :// si trova l’indicazione del nome di dominio dell’host, ovvero l’indirizzo del server su cui risiede la risorsa, che un software converte automaticamente in indirizzo IP avvalendosi del servizio DNS; in altri casi si può visualizzare direttamente l’indirizzo IP numerico, ma questa soluzione è più rara. Possiamo considerare il dominio anche come nome unico del sito web. In https://www.esempio.com, esempio.com è il dominio.
In genere, il percorso standard degli URL si ferma a questi parametri, ma esistono anche altri quattro elementi opzionali che si possono aggiungere all’indirizzo Web. La porta indica il servizio cui inoltrare la richiesta, in genere omesso perché si fa riferimento a porte standard associate al protocollo. Il percorso (pathname) all’interno del file system del server per identificare la risorsa richiesta; la query string è una stringa di caratteriche permette di trasmettere al server uno o vari parametri, mentre il fragment segnala una parte o una posizione interna alla risorsa. Il frammento è opzionale e viene utilizzato per puntare a una sezione specifica di una pagina; è preceduto da un simbolo #. Ad esempio, https://www.esempio.com/percorso/pagina#sezione punta direttamente alla sezione denominata “sezione” all’interno della pagina.
Più precisamente, il percorso specifica la posizione della risorsa all’interno del sito. Inizia con una barra singola / e può includere una serie di directory e sottodirectory. Ad esempio, in https://www.esempio.com/percorso/pagina, /percorso/pagina è il percorso che porta alla risorsa specifica. Alcuni URL includono come detto anche parametri di query, che sono coppie chiave-valore aggiunte alla fine dell’URL per passare informazioni aggiuntive al server. Questi parametri sono preceduti da un punto interrogativo ? e separati da un simbolo &. Un esempio potrebbe essere https://www.esempio.com/percorso/pagina?parametro=valore.
Sintetizzando le parti principali, abbiamo:
- Schema, che specifica la modalità di accesso alla risorsa.
- Server, parte che specifica il nome del computer in cui si trova la risorsa.
- Path, specifica la sequenza di directory che portano alla destinazione. Se la risorsa/resource viene omessa, la destinazione è l’ultima directory nel percorso.
- Resource / Risorsa, è la destinazione, in genere il nome di un file. Può trattarsi di un file semplice, contenente un singolo flusso binario di byte, o di un documento strutturato, contenente uno o più archivi e flussi binari di byte.
Indirizzo completo di un sito: esempi pratici
Per comprendere meglio come queste componenti lavorano insieme, esaminiamo alcuni esempi pratici di indirizzi completi di siti web.
Prendiamo l’URL https://www.esempio.com/blog/articolo?tag=seo#commenti. In questo caso, https è il protocollo che garantisce una connessione sicura. www.esempio.com è il dominio che identifica il sito web. Il percorso /blog/articolo ci porta alla specifica pagina del blog che contiene l’articolo. Il parametro di query tag=seo potrebbe essere utilizzato per filtrare o categorizzare il contenuto in base al tag “seo”. Infine, il frammento #commenti ci porta direttamente alla sezione dei commenti all’interno della pagina.
Un altro esempio potrebbe essere http://shop.esempio.com/prodotti/categoria/prodotto?id=12345. Qui, http è il protocollo, shop.esempio.com è il sottodominio che identifica una sezione specifica del sito dedicata allo shopping. Il percorso /prodotti/categoria/prodotto ci guida attraverso le directory fino alla pagina del prodotto specifico. Il parametro di query id=12345 potrebbe essere utilizzato per identificare univocamente il prodotto all’interno del database del sito.
URL: cosa significano indirizzi relativi, assoluti e parlanti
Come detto, gli URL sono alla base di tutti i siti web e rappresentano in modo standard la posizione di una generica risorsa a cui l’utente può accedere; la localizzazione di una pagina web può avvenire fornendo un indirizzo URL di tipo assoluto o relativo.
Questo è un altro tema che causa spesso dubbi amletici alla SEO: URL assoluti versus URL relativi dà vita a pareri sono più divisi tra chi promuove l’adozione di una struttura contro chi invece mette in risalto i benefici di quell’altra, spesso in relazione a eventuali preferenze di Google nell’eseguire la scansione e l’indicizzazione di questi indirizzi.
URL assoluti e URL relativi: definizioni, differenze e casi di utilizzo
Quando parliamo di link assoluti e relativi, ci riferiamo a due modi diversi di indicare l’indirizzo di una risorsa all’interno di un sito web.
L’URL assoluto è un indirizzo completo, che include tutti i dati necessari per accedere a quella pagina, file o risorsa – protocollo, server, percorso assoluto e nome del documento. Equivale a fornire a qualcuno l’indirizzo completo di un posto che sta cercando di raggiungere. Un link assoluto include l’intero URL, comprensivo di protocollo, dominio e percorso completo. Ad esempio, https://www.esempio.com/percorso/pagina è un link assoluto. Questo tipo di link è utile quando vogliamo garantire che l’utente o il motore di ricerca possa accedere alla risorsa da qualsiasi contesto, indipendentemente dalla pagina in cui si trova.
L’URL relativo è un indirizzo parziale, relativo appunto alla posizione in cui l’utente si trova in quel momento sul sito, e associano il codice alla struttura della directory o al file corrente. Riprendendo l’esempio delle indicazioni stradali, è come dire a una persona “vai alla serra dritto in fondo alla strada”. In ambito informatico, ad esempio, se ci troviamo su https://www.esempio.com/percorso/ e vogliamo linkare a una pagina all’interno della stessa directory, possiamo usare un link relativo come pagina.
In modo ancora più preciso, seguendo anche le indicazioni di questa guida di Microsoft, un URL assoluto usa il formato < schema://server/path/resource >, mentre “un URL relativo individua una risorsa usando un URL assoluto come punto di partenza“, in quanto l’URL completo della destinazione “viene specificato concatenando gli URL assoluti e relativi”.
L’URL relativo è solitamente composto solo dal percorso (path) e, facoltativamente, dalla risorsa, mentre sono assenti lo schema e il server. In pratica, con gli indirizzi relativi sembra mancare tutto, tranne il nome del file, e il browser comprende che per completare l’URL e raggiungere effettivamente la pagina deve utilizzare il path della cartella corrente.
Quando usare gli URL relativi
Gli URL relativi sono particolarmente utili in diversi scenari. Di base, questo tipo di link è utile per collegamenti interni, poiché rende più semplice la gestione e la manutenzione dei link all’interno del sito. Inoltre, i link relativi sono più flessibili in caso di cambiamenti di dominio o di struttura del sito.
Uno dei loro principali vantaggi è proprio la facilità di gestione. Quando utilizziamo URL relativi, possiamo appunto spostare intere sezioni del sito senza dover aggiornare manualmente ogni singolo link. Detta in altri termini, in caso di migrazione non sarà necessario procedere alla riscrittura di tutti gli URL delle pagine né a correggere i link interni tra le pagine del sito, perché queste risorse funzioneranno sempre correttamente indipendentemente dalla loro collocazione, senza errori di indirizzamento.
Un altro scenario in cui gli URL relativi sono preferibili è durante lo sviluppo e il testing del sito. Utilizzando URL relativi, possiamo testare il sito in ambienti diversi (come un server locale o un server di staging) senza dover modificare gli indirizzi dei link. Questo rende il processo di sviluppo più efficiente e meno soggetto a errori.
Inoltre, gli indirizzi relativi sono consigliati anche per i siti organizzati in directory, perché facilitano la gestione della moltitudine di pagine registrate e raggruppate in più cartelle, in quanto prevedono soltanto le informazioni strettamente necessarie per reperire le pagine all’interno del sito.
Tuttavia, è importante notare che gli URL relativi possono causare problemi se non sono utilizzati correttamente. Ad esempio, se non siamo attenti alla struttura delle directory, potremmo creare link rotti o errati. Pertanto, è essenziale avere una chiara comprensione della struttura del sito e utilizzare URL relativi solo quando siamo sicuri che non causeranno problemi di navigazione.
URL assoluti o relativi: qual è la scelta migliore per il sito
In termini pratici, impostare un URL assoluto o un URL relativo genera ovviamente una differenza per il sito.
Nel primo caso, l’indirizzo contiene più informazioni e fa riferimento preciso a una posizione unica e a un file unico; inoltre, l’uso di URL assoluti è obbligatorio per i link in uscita verso altri siti, che hanno quindi un nome di dominio diverso, perché altrimenti non possono essere correttamente individuati dal browser.
Il problema con gli URL assoluti nasce in caso di eventuali interventi di migrazione o trasferimento del sito, perché se spostiamo il sito su un altro server o un altro dominio, dobbiamo necessariamente riscrivere tutti gli indirizzi per consentire di raggiungere efficacemente le risorse.
È (anche) per questo motivo che, solitamente, si ritengono più preziosi e comodi gli URL relativi, che sono più brevi e più portabili – anche se, come sottolineato, ci sono comunque vari aspetti da considerare per eseguire i processi senza errori.
Quale opzione scegliere per la SEO
La differenza tra URL assoluto e URL relativo ha quindi una spiegazione tecnica e pratica; ma qual è la posizione di Google, e quindi qual è la scelta migliore per la SEO?
Secondo John Mueller, in realtà non c’è una soluzione preferita o perfetta perché, “se implementati correttamente, entrambi questi approcci portano esattamente alla stessa posizione” e quindi per la Ricerca Google “non importa affatto quale di questi si usa sul sito”.
In termini di ottimizzazione e di ranking, quindi, “Google tratta entrambi esattamente allo stesso modo”, e anzi possiamo “anche usare entrambi i tipi di URL all’interno dello stesso sito web, perché non c’è assolutamente nessuna differenza relativa”.
Ciò che conta per la Ricerca e, più in generale, per i motori di ricerca è avere a disposizione un URL univoco per elemento di contenuti, che consenta quindi di eseguire la scansione e indicizzare quei contenuti in modo da presentarli agli utenti, ma il modo in cui garantire questa richiesta è a nostra discrezione.
Che cosa significa URL parlante: definizione e vantaggi
Tornando poi al “dizionario degli URL” in ottica SEO e non solo, ci sono altre due espressioni che tornano di frequente, ovvero slug e URL parlante.
Un URL parlante è un indirizzo web che descrive chiaramente il contenuto della pagina utilizzando parole chiave pertinenti e facilmente comprensibili. A differenza degli URL generici o criptici, gli URL parlanti sono progettati per essere intuitivi sia per gli utenti che per i motori di ricerca. Ad esempio, un URL come https://www.esempio.com/guida-seo è molto più informativo e facile da ricordare rispetto a https://www.esempio.com/page?id=123.
I vantaggi degli URL parlanti sono molteplici. Innanzitutto, migliorano l’esperienza dell’utente, rendendo più facile capire di cosa tratta la pagina semplicemente leggendo l’URL. Questo può aumentare la probabilità che gli utenti clicchino sul link nei risultati di ricerca. Inoltre, gli URL parlanti possono migliorare la SEO del sito, poiché i motori di ricerca utilizzano le parole chiave presenti nell’URL per indicizzare e classificare le pagine. Un URL ben strutturato e descrittivo può quindi contribuire a migliorare il posizionamento nei risultati di ricerca.
Che cos’è lo slug e cosa significa
La porzione dell’URL con il percorso è anche chiamata slug.
Dal punto di vista tecnico, slug è quindi la parte finale di un URL, la stringa che identifica una specifica pagina o risorsa all’interno di un sito. È quindi l’elemento che fa la differenza per rendere un URL parlante.
Per esempio, nell’URL https://www.example.com/blog/my-first-post, lo slug è my-first-post, ed è un identificativo unico che viene utilizzato per riferirsi a quella specifica risorsa.
Il termine ha le sue radici nel giornalismo, dove “slug” si riferisce a una breve stringa di parole che identifica un articolo mentre è in fase di produzione, ed è stato poi adottato nel mondo del web.
Come creare URL parlanti: esempi e consigli per slug ottimizzati
Lo slug è quindi la parte variabile di un URL, quella su cui abbiamo più controllo e su cui in genere serve intervenire.
La scelta dello slug è importante perché influisce direttamente sulla leggibilità e sull’ottimizzazione per i motori di ricerca. Uno slug ben progettato può migliorare la visibilità della pagina nei risultati di ricerca e rendere l’URL più intuitivo per gli utenti. Utilizzare parole chiave pertinenti nello slug aiuta i motori di ricerca a comprendere meglio il contenuto della pagina e a classificarla di conseguenza.
Per creare e gestire in modo efficace un sito strutturato con URL parlanti servono attenzione e pianificazione.
Prima di tutto, è importante utilizzare parole chiave pertinenti che descrivano accuratamente il contenuto della pagina. Questo non solo aiuta i motori di ricerca a indicizzare la pagina, ma rende anche l’URL più intuitivo per gli utenti. Ad esempio, se stiamo creando una pagina su come ottimizzare gli URL, un URL parlante efficace potrebbe essere https://www.esempio.com/ottimizzazione-url.
In secondo luogo, è consigliabile mantenere gli URL brevi e concisi. Evitiamo parole inutili o ridondanti che possono rendere l’URL lungo e difficile da leggere. Ad esempio, anziché https://www.esempio.com/come-ottimizzare-gli-url-per-la-seo, possiamo optare per https://www.esempio.com/ottimizzazione-url-seo. Ricordiamoci sempre che uno slug troppo lungo può risultare difficile da leggere e ricordare.
Un altro suggerimento è utilizzare trattini per separare le parole all’interno dell’URL. I trattini sono interpretati dai motori di ricerca come spazi, rendendo l’URL più leggibile sia per gli utenti che per i motori di ricerca. Ad esempio, https://www.esempio.com/guida-seo è preferibile a https://www.esempio.com/guida_seo o https://www.esempio.com/guidaseo.
È anche importante evitare l’uso di caratteri speciali e numeri non necessari. Questi elementi possono rendere l’URL meno leggibile e più difficile da ricordare. Ad esempio, https://www.esempio.com/articolo-123 è meno efficace di https://www.esempio.com/articolo-seo.
Infine, testiamo sempre i nostri slug per assicurarci che siano chiari e descrittivi. Chiediamoci se un utente che vede lo slug per la prima volta può capire immediatamente di cosa tratta la pagina. Se la risposta è sì, allora abbiamo creato un URL parlante ottimizzato ed efficace.
URL e SEO: l’importanza per ranking e user experience
Come dicevamo nel nostro approfondimento sui 200 fattori di ranking, anche la strutturazione dell’indirizzo delle pagine può avere un’influenza sul posizionamento sui motori di ricerca, e dunque bisogna valutare vari aspetti quando ragioniamo sullo standard da applicare alle pagine del nostro sito.
La definizione di un percorso URL efficace può avere 3 effetti positivi per la SEO: impatta sul ranking, migliora l’user experience e rappresenta una potenziale anchor text per la condivisione della pagina.
- Indirizzo URL e ranking su Google
Per quanto riguarda il ranking, tralasciando discorsi su un ipotetico e potenziale rapporto diretto tra ottimizzazione dell’URL e posizionamento su Google, c’è comunque un elemento da non trascurare, quello della miglior leggibilità.
Più è facile per Google leggere e interpretare l’URL, maggiore sarà facile determinare la pertinenza e quindi i posizionamenti per una query di ricerca.
In termini pratici, poi, si ritiene che usare URL che contengono keyword possa essere un sistema per migliorare la visibilità del sito nelle ricerche, ma non bisogna commettere l’errore di realizzare percorsi inutili soltanto per inserire delle parole chiave nella stringa. In particolare, non dobbiamo cadere in banali errori SEO, e quindi dobbiamo ad esempio evitare il keyword stuffing, ovvero l’inserimento eccessivo di parole chiave, che può risultare controproducente. Un URL come https://www.esempio.com/consigli-seo è efficace perché include una parola chiave pertinente senza esagerare.
- Il rapporto tra URL e UX
Simile il discorso sull’user experience, perché un URL ben strutturato fornisce sia ai motori di ricerca che agli esseri umani indicazione facili da capire sul contenuto della pagina di destinazione.
Per questo motivo è preferibile realizzare un URL leggibile (human-readable) e semanticamente accurato, che dia un’idea chiara del topic della pagina e di cosa aspetta il visitatore che clicca sul link.
- L’URL come anchor text
In ultimo, un URL ben scritto può essere più facilmente copiato e incollato come link in forum, blog, social media network o altri contesti, diventando un anchor text ideale.
URL SEO Friendly: cosa significa e come sono
Le strutture di URL che rispettano i parametri sopra descritti si chiamano proprio SEO friendly. Questa definizione riguarda tutti gli indirizzi che descrivono in modo chiaro e con parole vere l’effettivo contenuto della pagina di riferimento, consentendo all’utente (e al motore di ricerca) di sapere immediatamente che tipo di informazioni aspettarsi. Per questo motivo, spesso si sintetizza che gli URL parlanti sono effettivamente URL SEO-friendly.
Detta in altri termini, URL SEO friendly sono quegli indirizzi web progettati per essere facilmente leggibili sia dagli utenti che dai motori di ricerca.
È anche una questione di approccio e di consapevolezza del fatto che ogni parte dell’URL deve essere pensata per fornire informazioni importanti sia ai visitatori del sito che ai motori di ricerca. Ad esempio, il campo dell’host è come il nome della strada in un indirizzo fisico, mentre il percorso, che indica la posizione specifica della risorsa all’interno del sito, è come il numero civico in un indirizzo fisico. Per questo si dice che un URL non è solo un indirizzo, ma un elemento chiave della nostra presenza online.
Ne consegue che un URL ben strutturato può aiutare i visitatori a capire dove si trovano e cosa stanno guardando, e può aiutare i motori di ricerca a capire di cosa parla la pagina e come dovrebbe essere indicizzata. È come se stessimo dando indicazioni a un amico che visita la nostra casa per la prima volta: un indirizzo chiaro e preciso lo aiuterà a trovare la strada senza problemi.
Per impostare efficacemente tali indirizzi valgono grosso modo le indicazioni fornite prima.
Innanzitutto, un URL SEO friendly è chiaro e descrittivo, possibilmente breve. Deve fornire un’indicazione precisa del contenuto della pagina, utilizzando parole chiave pertinenti, che abbiamo individuato come centrali per il topic o che comunque fanno riferimento specifico al contenuto della pagina. Questo non solo aiuta i motori di ricerca a comprendere meglio il contenuto della pagina, ma rende anche più facile per gli utenti ricordare e condividere l’URL. Ad esempio, un URL come https://www.esempio.com/blog/come-ottimizzare-url è molto più efficace di un URL generico e non descrittivo come https://www.esempio.com/page?id=123.
L’obiettivo è avere un indirizzo conciso – la lunghezza consigliata dalle best practices è tra i 50 e i 60 caratteri, evitando di superare i 115 caratteri per evitare problemi, chiaro e pertinente, che possa servire all’utente di comprendere immediatamente la sua correlazione con il contenuto a cui è interessato.
Inoltre, gli URL SEO friendly evitano l’uso di caratteri speciali e numeri non necessari, che possono confondere sia gli utenti che i motori di ricerca. Utilizzare trattini per separare le parole è una pratica comune e raccomandata, poiché i motori di ricerca interpretano i trattini come spazi. Ad esempio, https://www.esempio.com/guida-seo è preferibile a https://www.esempio.com/guida_seo.
Anche in questo caso, il nostro riferimento deve essere l’utente ancor prima che il motore di ricerca, cercando di assicurare una facile accessibilità e un buon livello di esperienza a chi scopre il sito tra i risultati di una ricerca di Google. Si ritiene, infatti, che un URL composto in maniera molto distante dal contenuto in pagina o carico di parametri e caratteri non leggibili possa peggiorare il bounce rate e disincentivare la permanenza dei lettori sulle pagine.
Dal punto di vista strategico, una struttura URL SEO friendly può:
- facilitare enormemente la ricerca dell’utente.
- contribuire a conferire un maggiore peso al ranking nelle SERP di Google
- ottimizzare il traffico della pagina, favorendo un aumento di visibilità e di numero dei clic.
Le best practices SEO per gli URL
Ecco dunque che si delineano alcune best practices SEO per la gestione degli URL:
- Mantenere il più possibile indirizzi semplici, pertinenti, convincenti e curati: questa è la chiave per convincere sia gli utenti sia i motori di ricerca.
- Anche se, come detto, negli URL è possibile includere numeri e codici ID, la migliore pratica è quella di usare parole che le persone possono comprendere, utilizzando percorsi semanticamente corretti e leggibili dagli utenti.
- Gli URL dovrebbero essere definitivi ma concisi: semplicemente leggendo l’URL un utente e un motore di ricerca dovrebbero capire cosa aspettarsi sulla pagina.
- Per agevolare la leggibilità utilizzare i trattini per separare le parole. Si consiglia di evitare underscore, spazi o altri caratteri per separare le parole: se però su un sito ci sono tutti gli Url con underscore, è sconsigliato cambiarli in corso d’opera.
- Gli URL sono case sensitive, per cui è meglio usare lettere minuscole perché in alcuni casi le lettere maiuscole possono causare problemi con pagine duplicate (o comunque è meglio usare una linea coerente).
- Se possibile, evitare l’uso di parametri URL, che possono creare problemi con il tracking e il contenuto duplicato. Ad ogni modo, anche quando non è possibile farne a meno, è bene usare i parametri URL con parsimonia.
Lunghezza massima degli URL: cosa dice Google
A proposito dell’ottimizzazione della struttura è necessario un approfondimento riguardante la lunghezza degli URL ideale per la SEO, un tema che è stato spesso al centro del dibattito nella community internazionale, spingendo più volte Google – e in particolare il Search Advocate John Mueller – a intervenire per offrire chiarimenti e spiegazioni su ciò che è ritenuto SEO friendly per il motore di ricerca.
Non esiste una lunghezza massima ufficiale per gli URL, ma è generalmente consigliabile mantenerli sotto i 100 caratteri. URL troppo lunghi possono essere troncati negli snippet dei risultati di ricerca, rendendo difficile per gli utenti comprendere il contenuto della pagina. Inoltre, URL più brevi tendono a essere più facili da leggere, ricordare e condividere.
Per mantenere gli URL brevi e concisi, è utile eliminare parole inutili e ridondanti. Ad esempio, anziché utilizzare un URL come https://www.esempio.com/i-nostri-servizi-di-web-design-professionale, possiamo optare per https://www.esempio.com/servizi-web-design. Questo non solo riduce la lunghezza dell’URL, ma lo rende anche più chiaro e diretto.
Inoltre, è importante evitare l’uso eccessivo di sottodirectory. Ogni livello aggiuntivo nella struttura dell’URL può aumentare la sua lunghezza e complessità. Un URL come https://www.esempio.com/blog/2023/ottobre/guida-seo può essere semplificato in https://www.esempio.com/blog/guida-seo, mantenendo comunque tutte le informazioni rilevanti.
Il consiglio di massima è che, anche se la gestione degli URL non offre nessun effetto diretto in termini di ranking, ha comunque un impatto sul tipo di esperienza fornita agli utenti, sia in senso buono che in modo peggiorativo: se stiamo quindi valutando le opzioni per gestire gli indirizzi dei nostri contenuti in ottica SEO, è opportuno dedicare una (seppur minima) attenzione alla effettiva lunghezza degli URL, cercando di evitare alcuni errori che si possono rivelare dannosi.
La rivelazione che arriva dal Googler nel corso di un hangout su YouTube è molto chiara, e poi ribadita ulteriormente in un appuntamento con #AskGooglebot: secondo John Mueller, l’URL ideale non dovrebbe mai superare i mille caratteri, anche se “immagino che si debba lavorare molto per creare indirizzi così lunghi”, ironizza.
Il consiglio finale di Google è semplice: anche se i browser Web possono gestire lunghezze fino a un massimo di duemila caratteri, gli URL di un sito dovrebbero essere brevi e non superare mai la soglia dei 1000 caratteri. È chiaro che un indirizzo più conciso è tendenzialmente preferibile, anche per questioni di condivisibilità e leggibilità da parte degli utenti umani, ma per i motori di ricerca non ci sono problemi fino a quando non si arriva alle quattro cifre.
Le indicazioni di Google sulla struttura URL più efficace
All’interno delle linee guida SEO di Google c’è un capitolo dedicato alla gestione più corretta degli indirizzi web, che fornisce alcuni esempi di pratiche consigliate e di potenziali errori nella creazione degli URL, suggerendo anche metodi per risolvere i problemi più comuni.
Questa guida specifica innanzitutto quali caratteri supporta la Ricerca Google negli URL, chiarendo che “Google supporta gli URL come definiti da RFC 3986“. Inoltre, i caratteri definiti dallo standard come riservati devono essere codificati in percentuale; i caratteri ASCII non riservati possono essere lasciati nella forma non codificata, mentre, i caratteri nell’intervallo non ASCII devono essere codificati in UTF-8.
Sempre come indicazione di massima, poi, Google invita, quando possibile, a usare parole leggibili piuttosto che numeri ID lunghi negli URL.
Sul fronte pratico, questi sono alcuni dei casi specifici analizzati dal documento:
- Forme consigliate
- Parole semplici e descrittive nell’URL – https://en.wikipedia.org/wiki/Aviation
- Parole localizzate nell’URL, se applicabile – https://www.example.com/lebensmittel/pfefferminz
- Utilizzo della codifica UTF-8 in base alle necessità.

Negli esempi dell’immagine qui sopra, vediamo rispettivamente l’uso della codifica UTF-8 per i caratteri arabi, per i caratteri cinesi, per l’umlaut (i due puntini sopra le vocali che si trovano in alcune lingue, come il tedesco, e che tecnicamente sono un segno diacritico che indica una variazione nella pronuncia di quella vocale) e per le emoji nell’URL.
Ancora, se il sito è multiregionale potrebbe essere meglio utilizzare una struttura di URL che semplifichi il targeting geografico, e in particolare è consigliato l’uso di:
- Dominio specifico del Paese – https://example.de
- Sottodirectory specifica del Paese con gTLD – https://example.com/de/
Inoltre, Google suggerisce di preferire l’utilizzo di trattini al posto dei trattini bassi per separare le parole negli URL, che consente agli utenti e ai motori di ricerca di identificare più facilmente i concetti contenuti nell’URL.
- Utilizzo di trattini (-) – https://www.example.com/summer-clothing/filter?color-profile=dark-grey
- Forme sconsigliate
- Utilizzo di caratteri non ASCII nell’URL, come nell’immagine sotto (che in pratica rappresenta la scelta opposta rispetto a quelle suggerite in precedenza)
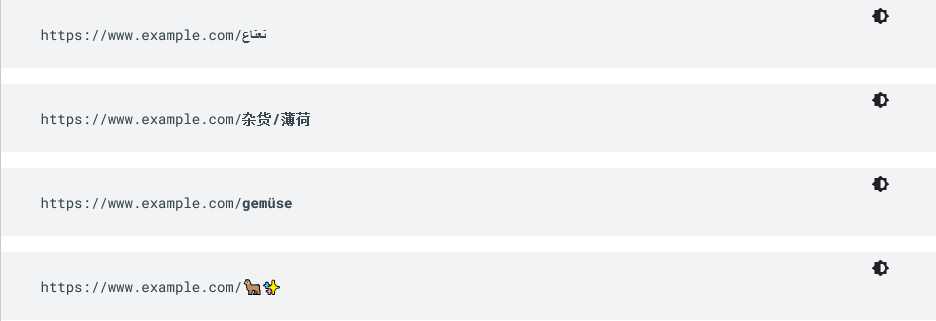
- Numeri ID lunghi e illeggibili nell’URL – https://www.example.com/index.php?id_sezione=360&sid=3a5ebc944f41daa6f849f730f1
- Utilizzo di underscore, i trattini bassi (_) – https://www.example.com/summer_clothing/filter?color_profile=dark_grey
- Utilizzo di parole unite negli URL – https://www.example.com/greendress
Come gestire bene la struttura URL
Queste buone pratiche valgono per tutte le tipologie di URL e per tutte le scelte. Anche se alcuni siti utilizzano parametri, altri utilizzano cartelle con nomi di file e ognuno gestisce gli URL in modo leggermente diverso, in linea di massima non c’è una soluzione ideale o preferita da Google.
Più precisamente, Google usa “gli URL come identificatori” e non dà particolare importanza a elementi come la lunghezza o né il numero di slash presenti nell’indirizzo, a patto di non esagerare e non complicare inutilmente le scansioni dei crawler.
C’è solo una sola parte dei sistemi di Google in cui la lunghezza dell’URL gioca un ruolo: la canonicalizzazione, il meccanismo che entra in gioco quando il motore di ricerca trova più versioni di una pagina sullo stesso sito web e deve scegliere un URL da utilizzare per l’indicizzazione. In questi casi, infatti, Google tende a selezionare “un URL più corto e pulito” rispetto a un indirizzo più lungo e complesso. Non si tratta di un aspetto che influisce sul ranking della pagina, ma “è puramente una questione di quale URL viene mostrato nella Ricerca”, chiarisce ancora.
In definitiva, quello che serve per la SEO e per l’usabilità del sito è che Google possa “prendere quell’URL che hai, scansionarlo, raccogliere il presente su quell’indirizzo e indicizzarlo”. Ovvero, che la stringa di caratteri sia leggibile, interpretabile da Googlebot e rimandi a una risorsa indicizzabile. Tutte le altre questioni sono affidate al proprietario del sito, al webmaster ed eventualmente ai consulenti SEO che ci lavorano!
Come usare SEOZoom per ottimizzare gli URL SEO
In SEOZoom c’è uno strumento avanzato progettato appositamente per ottimizzare gli URL del nostro sito in ottica SEO. URL Inspector esegue una scansione approfondita di tutte le pagine del sito a progetto, analizzando le keyword posizionate su Google, per aiutarci a capire rapidamente se abbiamo ottimizzato correttamente i title e gli URL rispetto ai principali competitor e alle keyword principali per cui ci siamo posizionati, quelle con il traffico stimato più elevato.
L’analisi dettagliata ci consente di individuare le pagine non perfettamente ottimizzate, sulle quali dovremmo intervenire per migliorare la nostra strategia SEO. In particolare, troviamo informazioni sul livello di ottimizzazione raggiunto dai competitor, mostrando il numero di pagine che hanno utilizzato la keyword nel title: questo ci aiuta a valutare le nostre possibilità di raggiungere la top 10 di Google con contenuti adeguati. Le colonne TM (Title Match) e PM (Partial Match) nella tabella ci informano sul numero di pagine in top 10 che hanno adottato l’exact match o il partial match della keyword nel titolo.
L’algoritmo di SEOZoom non si limita a identificare le pagine da ottimizzare, ma offre anche insights per la creazione di nuovi contenuti: analizzando gli URL ottimizzati e non ottimizzati, possiamo infatti ottenere idee per nuovi contenuti, con suggerimenti sulle parole chiave da utilizzare e su cui incentrare il lavoro. Ad esempio, possiamo creare nuove pagine specifiche per competere per keyword non pienamente coperte dai contenuti esistenti, in modo da evitare la cannibalizzazione dei contenuti e a migliorare la nostra strategia editoriale.
C?è però un’avvertenza cruciale: è fondamentale verificare che i suggerimenti automatizzati del tool siano in linea con l’intento del contenuto e con gli obiettivi strategici impostati. Questo è particolarmente importante perché Google potrebbe posizionare le pagine per keyword diverse da quelle previste, il che potrebbe non essere funzionale per i nostri interessi di business. Per questo, URL Inspector è pensato per utenti esperti e professionisti del settore e non è immediatamente adatto a principianti SEO: non basta applicare automaticamente i suggerimenti forniti, ma è necessaria una valutazione approfondita che tenga conto delle caratteristiche del sito, del livello dei competitor e delle scelte imprenditoriali.
URL e SEO: i problemi comuni per la gestione degli indirizzi
La risorsa di Google ci è utile anche per analizzare alcune situazioni critiche comuni cui possiamo andare incontro nella gestione degli indirizzi del nostro sito.
In particolare, la guida sottolinea come gli URL estremamente complessi, e soprattutto quelli contenenti più parametri, possono causare problemi ai crawler creando numeri inutilmente elevati di URL che puntano a contenuti identici o simili sul sito. Di conseguenza, Googlebot potrebbe utilizzare molta più larghezza di banda del necessario o non essere in grado di indicizzare completamente tutti i contenuti del sito – insomma, problemi anche col crawl budget.
Questo eccesso immotivato di URL può essere causato da una serie di problemi, tra cui:
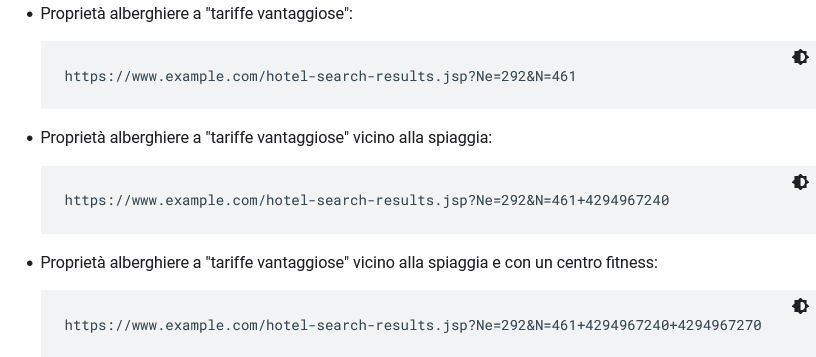
- Filtri aggiuntivi di un gruppo di elementi.Molti siti forniscono visualizzazioni diverse dello stesso insieme di elementi o risultati di ricerca, ad esempio quando consentono all’utente di filtrare questo gruppo utilizzando criteri definiti (ad esempio: mostrami gli hotel sulla spiaggia). Quando i filtri possono essere combinati per addizione (ad esempio: hotel sulla spiaggia e con un centro fitness), il numero di URL (visualizzazioni di dati) nei siti aumenta a dismisura. La creazione di un numero elevato di elenchi di hotel con lievi differenze è ridondante, perché Googlebot ha bisogno di vedere solo pochi elenchi per raggiungere la pagina di ciascun hotel, come negli esempi in immagine.
- Generazione dinamica dei documenti: questa operazione può comportare leggere modifiche, a causa di contatori, timestamp o presenza di pubblicità.
- Parametri problematici nell’URL: gli ID di sessione, ad esempio, possono creare enormi quantità di duplicati e un numero molto elevato di URL.
- Parametri di ordinamento: alcuni siti di shopping di grandi dimensioni forniscono più modalità di ordinamento degli stessi articoli e ciò comporta un notevole aumento del numero di URL.
- Parametri irrilevanti nell’URL, ad esempio parametri di referral.
- Problemi del calendario: un calendario generato dinamicamente può creare link a date passate e future senza restrizioni sulle date di inizio e di fine.
- Link relativi inaccessibili: i link relativi inaccessibili e interrotti sono spesso causa di spazi infiniti. Questo problema si verifica soprattutto quando ci sono elementi del percorso ripetuti.
Come risolvere i principali problemi con gli URL
Anche alla luce delle situazioni appena descritte, la guida si conclude con una serie di indicazioni pratiche per evitare potenziali problemi relativi alla struttura degli URL.
- Creare una struttura URL semplice. In linea di massima, la soluzione ideale sarebbe organizzare i contenuti in modo che gli URL siano costruiti in modo logico e nel modo più comprensibile per gli esseri umani.
- Usare un file robots.txt per bloccare l’accesso di Googlebot agli URL problematici. Valutare in particolare la possibilità di bloccare gli URL dinamici, come gli URL che generano risultati di ricerca o gli URL che possono creare spazi infiniti, come i calendari; l’utilizzo di espressioni regolari nel file robots.txt può consentirci di bloccare facilmente un gran numero di URL.
- Dove possibile, non utilizzare ID sessione negli URL, sostituendoli con i cookie.
- Se il server web non è case sensitive – e quindi tratta allo stesso modo testo maiuscolo e minuscolo in un URL – è opportuno convertire tutto il testo nello stesso formato in modo che sia più facile per Google determinare che gli URL fanno riferimento alla stessa pagina.
- Ridurre la lunghezza degli URL, se possibile, eliminando i parametri non necessari.
- Se il sito include un calendario infinito, aggiungere un attributo nofollow ai link che rimandano a pagine future del calendario create dinamicamente.
- Verificare l’eventuale presenza di link relativi inaccessibili nel sito.
Il valore degli URL per la SEO e l’usabilità del sito
Per la SEO e per l’usabilità del sito ci sono alcune norme da rispettare nei confronti degli URL, come detto, a cominciare dai criteri di leggibilità, possibilità di rendere l’indirizzo interpretabile da Googlebot e rimando a una risorsa ugualmente accessibile per l’indicizzazione sul motore di ricerca.
Premesso questo, ci sono situazioni in cui si può valutare l’ipotesi di trasformare la struttura usata per gli URL e di optare per una soluzione maggiormente SEO-friendly (almeno in apparenza): tecnicamente, si può procedere con un intervento di migrazione degli URL del sito che risulta utile soprattutto quando ci sono problemi e si esegue con regole di riscrittura.
In linea di massima, però, bisognerebbe cercare di evitare il ricorso a queste tecniche perché ci sono tanti errori che possono compromettere la salute del progetto, e soprattutto bisogna sempre farle affidandosi a professionisti esperti perché perdere o lasciare qualcosa nella fase di rinnovamento della struttura degli URL può costare classifiche e traffico al sito.
Dunque, è il caso di ponderare con attenzione la situazione e chiedersi perché si pensa di cambiare URL del sito. Ci sono momenti in cui tale modifica è inevitabile: tra i motivi più comuni ci sono il rebranding, la migrazione del sito o la riprogettazione profonda del sito e di alcuni elementi base (il nome di dominio, tipi di prodotto, focus dei topic), cambi di piattaforma CMS che non consente più di conservare gli stessi indirizzi, o presenza di problemi come date obsolete negli indirizzi, elementi inutili, spostamento di intere directory.
Tuttavia, secondo gli esperti in altre circostanze meno urgenti sarebbe sempre meglio evitare di cambiare la struttura degli URL, anche a prescindere dai ragionamenti SEO. Solo per fare degli esempi, una modifica potrebbe non far più funzionare i segnalibri che gli utenti hanno salvato nel proprio browser dalla visita del sito o dalle precedenti campagne di email marketing o newsletter: ogni stravolgimento della struttura dell’URL rimuove la relazione diretta che l’utente ha con un sito.
Non meno complessa è la gestione dei redirect 301: se il sito è stato sottoposto a una completa ristrutturazione, potrebbe non esserci una pagina diretta a cui reinviare l’utente, e quindi nel processo si rischia di perdere quel traffico (e il posizionamento precedentemente guadagnato).
I pericoli SEO dello stravolgimento degli URL
E veniamo quindi ai pericoli legati alla SEO che queste modifiche possono provocare (e che quindi dovrebbero invitare quanto meno a una riflessione lunga prima di lanciarsi nell’operazione): i principali sono la gestione dei link e dei precedenti backlink ricevuti e il tempo necessario a Google per riscoprire le pagine del sito attraverso i nuovi URL.
- Rischio di perdere backlink
Per quanto riguarda il primo punto, sappiamo che i link sono ancora uno dei principali fattori di ranking e che la qualità e la quantità dei collegamenti sono un segnale e una delle misure con cui Google stima la potenziale pertinenza e affidabilità di un sito. In questo processo non bisogna quindi dimenticare tutti i link esterni al sito Web, che bisognerebbe cercare di modificare e aggiornare: operazione non sempre possibile e non sempre facile, perché potrebbe essere necessario contattare i vari webmaster per chiedere le modifiche agli indirizzi. Più in generale, poi, bisogna cambiare anche le campagne a pagamento, le piattaforme social e la pubblicità off-site.
- Curare bene i link interni
Quando si realizza una riprogettazione del sito si rischia di trascurare poi i link interni, riducendo così il valore SEO del nuovo progetto: è perciò fondamentale creare una sitemap “prima e dopo”, assicurandosi di reindirizzare le pagine da abbandonare (ma ancora utili anche per il traffico) tramite un 301 permanente a una nuova pagina che corrisponda a quella precedente in termini di topic.
Se invece si esegue un redirect verso una pagina con contenuto non simile al precedente si potrebbe perdere PageRank, perché Google potrebbe rimuovere il valore di tali collegamenti. Allo stesso modo, non si dovrebbe mai reindirizzare tutte le pagine sulla home page o su una pagina di livello superiore, perché quei backlink potrebbero essere svalutati in quanto non attinenti.
- A Google serve tempo per riscoprire i nuovi URL
L’altro fronte problematico riguarda i tempi che servono a Google per riscoprire ed elaborare correttamente i nuovi URL del sito, e durante questo periodo è possibile riscontrare una flessione delle classifiche e quindi del traffico organico. Certo, si tratta di una eventualità e di una situazione temporanea (se si esegue correttamente il processo di migrazione), ma comunque è un fattore da tenere in considerazione quando si valuta se è il caso di cambiare struttura degli Url. Per questo motivo potrebbe essere utile pianificare questi interventi durante il periodo meno impegnativo dell’anno e di seguire tutti i protocolli appropriati per evitare errori.
Il consiglio di Google: non cambiare URL se non è necessario
In conclusione, ricordiamo cosa dice il nostro John Mueller (in un commento su reddit) sulla modifica della struttura degli URL, perché sintetizza tutto quello che abbiamo scritto fin qui:
I’d avoid changing URLs unless you have a really good reason to do so, and you’re sure that they’ll remain like that in the long run.
ovvero, in italiano, “eviterei di cambiare gli URL a meno che tu non abbia una buona ragione per farlo e che tu non sia sicuro che rimarranno così a lungo termine”.
