
Sitemap: what it is, how to submit it to Google, and why it is useful for a site
We can define it as a real map that helps search engines make their way through our website, finding (and analyzing) the URLs we enter more easily, and it is a crucial element in building a positive dialogue between our site and Googlebot, especially in having pages that are relevant to us discovered. Our insights today bring us to a seemingly simple, yet often underestimated topic: what is a sitemap and why can it be useful to communicate it to Google and other search engines?
What is a sitemap
The definition of a sitemap is easy: it is a file that contains all the URLs of a site, listed according to a hierarchy set during creation. Initially, the point of the sitemap was to facilitate user navigation, like a real sitemap, but its usefulness also extends to the activities of crawling and indexing by search engine crawlers, who thus can understand the structure of the site sooner and better because of the information they find about the relationships between pages.
More specifically, this file “is a signal of what URLs on your site you want Google to scan” and can provide information about newly created or modified URLs.
What the sitemap is for
With the sitemap, a search engine crawler such as Googlebot can crawl your site more efficiently because it has an overview of the available content, with indications of what resources are present and the path to them.
In general, web crawlers can find most content if a site’s pages are linked properly: using a sitemap is a sure way for search engines to more quickly and accurately understand the entire structure of the site.
The usefulness of the Sitemap in Google
In fact, the sitemap file allows webmasters to submit available site pages for scanning and provide information to crawlers about the pages themselves and the resources presented on the site, highlighting as mentioned the hierarchies and correlations between the various elements; in addition, it also contains precise details about the pages such as date of last update, frequency of modification and any versions in other languages of the pages.
Sitemap’s formats
There are essentially two most widely used Sitemap formats: the first is the HTML Sitemap file, which is older and also used to facilitate user navigation and thus improve the user experience.
More specific is the XML Sitemap format, invented by Google in 2005 (and then called Google Sitemaps) and later adopted by other search engines as well: there is a real protocol, regulated by the Attribution-ShareAlike Creative Commons License, and this has made it possible to extend the map to other search engines as well.
To these two types we must also add for completeness the three special types of sitemaps, which are related to particular categories of content published on the pages, and therefore specific to sites hosting images, videos and news, and facilitate the understanding of these resources by search engines.

What is the XML Sitemap
Google’s Webmaster’s guide contains an entry on XML Sitemaps, which are defined as “an XML file containing a site’s URLs along with their associated metadata,” i.e., importance relative to the site’s other URLs, general frequency of changes, or date of last update, which allows “search engines to crawl the site more efficiently.” With this system, dynamic sites can also provide correct URLs and secure smarter indexing by also telling the search engine about information such as the date of the page’s last update and the presence of versions in other languages.
The limitations of Sitemaps
There are two basic requirements to be met: all sitemap formats cannot exceed the 50 MB and 50,000 URL limit. If your site has a larger file size or one containing multiple URLs you will need to split the list into several sitemaps or create a single Sitemap Index file (which encloses a list of sitemaps) to submit to Google.
Sitemap usage and page indexing
It is again Google that clarifies precisely some aspects on this issue: first, “the use of the Sitemap Protocol does not guarantee the inclusion of web pages in search engines,” and therefore there is no certainty that the pages in the Sitemap file are all then actually indexed, because Googlebot acts according to its own criteria and respecting its own complex algorithms, which are not affected by the Sitemap.
Use of Sitemap and Google ranking
There is also some useful information about ranking: the Sitemap does not affect the ranking of a site’s pages in search results, but the priority assigned to a page through the Sitemap could potentially be a ranking factor.
Why use the Sitemap according to Google
After these premises, what is the specific purpose of using a Sitemap? Obviously, all sites can benefit from a better crawl, but there are special cases where Google strongly recommends using these files, as we read in this guide on the subject. First of all, very large sites should use the Sitemap to communicate new or recently updated pages to crawlers, who might otherwise neglect crawling these resources; even more useful is the map if the site has many isolated or poorly linked pages of content, which are therefore at risk of not being considered by Google.
Sites that must use the Sitemap
The Sitemap is then recommended for new sites with few incoming backlinks: in this case, Google and its crawler may have difficulty finding the site because no paths between Web links are highlighted. Finally, they urge using the map if the site “uses multimedia content, is displayed in Google News, or uses other sitemap-compatible annotations,” adding that if “appropriate, Google may consider other information contained in the sitemaps to use for search purposes.”
And so, to recap, the sitemap is useful if:
- The site is large, because generally on large sites it is more difficult to make sure that every page is linked from at least one other page on the site, and therefore Googlebot is more likely to miss some of the new pages.
- The site is new and receives few backlinks. Googlebot and other web crawlers crawl the Web by following links from one page to another, so in the absence of such links Googlebot may not detect the pages.
- The site has a lot of multimedia content (video, images) or is displayed in Google News, because we can provide additional information to the crawlers through specific sitemaps.
Which sites may not need a sitemap
While these are the cases where Google strongly recommends submitting a sitemap, there are situations where it is not so necessary to provide the file. In particular, we may not need a sitemap if:
- The site is “small” and hosts about 500 pages or less (calculating only the pages we think should be included in search results).
- The site is fully internally linked and Google can therefore find all the important pages by following the links starting from the home page.
- We do not publish many media files (videos, images) or news pages that we wish to display in search results. Sitemaps can help Google find and understand video and image files or news articles on the site, but we do not require these results to be displayed in Search, we may not submit the file.
How to create a Sitemap
To generate a sitemap you must first decide which pages of the site you want to point to and have Google scan them, establishing the canonical version of each page. The second step is to choose which Sitemap format to use, and then get to work with text editors or special software, or rely on an easier and faster alternative that is affordable for everyone.
Creating a Sitemap with Sitemap Generator
If in fact the more experienced can create the file manually, there are many resources on the Web that allow you to generate sitemaps automatically: there is even a page on Google that lists Web Sitemap generators, broken down by “server-side programs,” “CMS and other plugins,” “Downloadable Tools,” “Online Generators/Services,” and “CMS with integrated Sitemap generators.” Also noted are tools for generating sitemaps for Google News and “Code Snippets/Libraries.”
Whichever you choose, it is essential to make the created Sitemap available to Google right away, either by adding it to the robots.txt file or by submitting it directly to Search Console.
Benefits of the Sitemap
Ultimately, then, using a Sitemap is a method of making life easier for crawlers and providing a map of your site’s content to Googlebot. While it does not guarantee that the indicated items will then actually be crawled and indexed, it is recommended that you always use a Sitemap because “in most cases, the existence of a Sitemap is still a benefit to your site and you will never be penalized for having one,” as Google puts it.
Creating and submitting a sitemap, Google’s new guide
In February 2023, Google updated the official documentation supporting the creation and submission of a sitemap, pointing out the recommended procedures for performing all the steps correctly.
Specifically, the guide describes how to create a sitemap and make it available to Google, starting by indicating which formats are supported-that is, those defined by the sitemaps protocol – and pointing out that Google does not have a specific preference, not least because each sitemap has its advantages and disadvantages (and therefore the choice on the type depends on what turns out to be most appropriate for our site and our configuration).
Sitemap formats for Google: the pros and cons
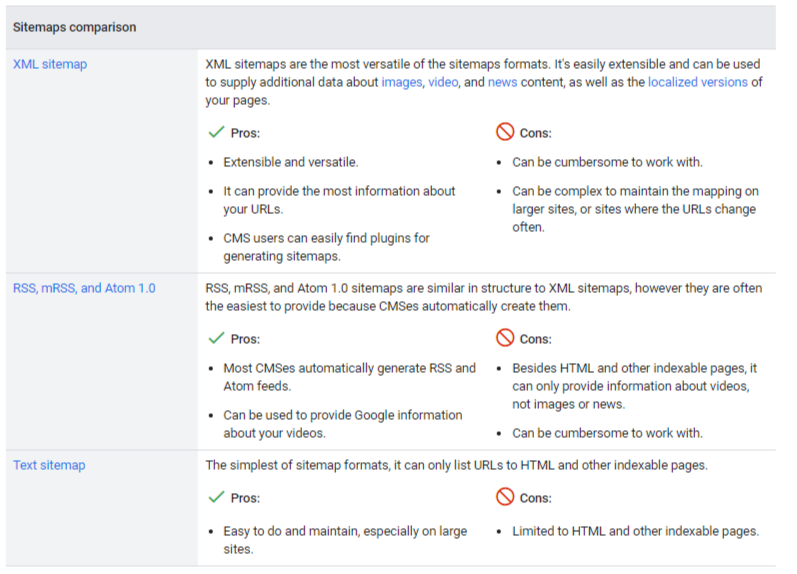
As you can also see from the screenshot below, Google recognizes and accepts three formats:
- XML sitemaps are the most versatile, because they are easy to extend and modify, and can also be used to provide additional data on images, videos and news content, as well as for localized versions of pages. Among the pros, then, are precisely being extendable and versatile, as well as the ability to provide a lot of URL information and to be easily generated even with plugins for major CMSs; among the cons, working with them is not always convenient and, in particular, it can be complex to maintain the mapping on larger sites or sites where URLs change frequently.
- RSS, mRSS, and Atom 1.0 have a similar structure to XML sitemaps; however, they are often easier to provide because CMSs create them automatically. Thus, the pros include precisely the ability to automatically generate RSS and Atom feeds through CMSs and the ability to also use these files to provide Google with information about videos, while the cons include the inability to provide information about images or news and a general difficulty in working with them.
- Text is the simplest of formats and can list only HTML URLs and other indexable pages. Its advantage is precisely the ease of use and management, especially on large sites, but it has the disadvantage of being limited to HTML and other indexable pages.
The characteristics of the various sitemap formats
Going even deeper, Google describes the main features of the three formats available for creating sitemaps.
- As mentioned, the XML sitemap is the most versatile of the supported formats: using the extensions supported by Google, we can also provide additional information about images, videos and news content , as well as localized versions of pages. In the example below, the map includes the location of a single URL:

In addition, the guide points out that:
-
- As with all XML files, all tag values must use escaped entity codes.
- Google ignores <priority> and <changefreq> values.
- Google uses the <lastmod> value if it is consistently and verifiably accurate (e.g., by comparing it to the last change on the page).
- The RSS, mRSS and Atom 1.0 sitemap is recommended if we have a blog with an RSS or Atom feed, and just send the feed URL as a sitemap. Most blog software can create a feed for us, but we should be aware that this feed only provides information about recent URLs.
Among additional notes, Google reminds us that:
-
- Google accepts RSS 2.0 and Atom 1.0 feeds.
- We can use an mRSS (multimedia RSS) feed to provide Google with details about video content on the site.
- As with all XML files, all tag values must use escaped entity codes.
- Lastly, if the sitemap includes only web page URLs, we can provide Google with a simple text file containing one URL per line, as in the example:

In addition, Google reminds us that:
-
- We cannot put anything but URLs in the sitemap file.
- We can name the text file as we prefer, as long as we leave the extension .txt (for example, sitemap.txt).
How to create a sitemap: tools and methods
After deciding which URLs to include in the sitemap, we have several ways to create the file, depending on the architecture and size of the site:
- Let your CMS generate a sitemap. If we use a CMS such as WordPress, Wix or Blogger, it is likely that the sitemap is already made available to search engines.
- Manually create a sitemap (for files with fewer than a few dozen URLs). To do this, simply use a text editor such as Windows Notepad or Nano (Linux, macOS) and follow the syntax described earlier, taking care to name the file with characters allowed in a URL. This process is doable even for larger files, but it is tedious and difficult to maintain in the long run.
- Automatically generate a Sitemap (for files with more than a few dozen URLs). There are various tools that can generate a sitemap but, according to Google, the best way is to have the website software generate it automatically. For example, we can extract the site URLs from the database and then export the URLs to the screen or to the actual file on the web server.
How to submit the sitemap to Google
Whereas, submitting a sitemap is only a suggestion and does not guarantee that Google will download or use it to crawl URLs on the site, the guide indicates the different ways to make the sitemap available to Google. That is, we can:
- Submit a sitemap in Search Console using the Sitemap report, which will allow us to see when Googlebot accessed the sitemap and also potential processing errors.
- Use the Search Console API to programmatically submit a sitemap.
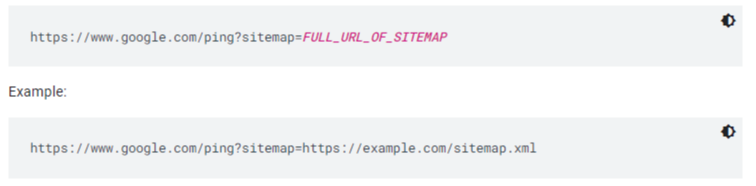
- Use the ping tool. Send a GET request in the browser or from the command line to this address, specifying the full sitemap URL – making sure that the Sitemap file is accessible to Googlebot:
- Enter the following line anywhere in the robots.txt file, specifying the location of the sitemap, which Google will find the next time it scans the robots.txt file.

- Use WebSub to transmit changes to search engines, including Google (but only if we use Atom or RSS).
Methods for cross-submitting sitemaps for multiple sites
If we manage multiple websites, we can simplify the submission process by creating one or more sitemaps that include the URLs of all verified sites and saving the sitemaps in a single location. Methods for this multiple, cross-site submission are:
- A single sitemap that includes URLs for multiple websites, including sites from different domains. For example, the sitemap located at https://host1.example.com/sitemap.xml may include the following URLs.
- https://host1.example.com
- https://host2.example.com
- https://host3.example.com
- https://host1.example1.com
- https://host1.example.ch
Individual sitemaps (one for each site) that all reside in one location.
-
- https://host1.example.com/host1-example-sitemap.xml
- https://host1.example.com/host2-example-sitemap.xml
- https://host1.example.com/host3-example-sitemap.xml
- https://host1.example.com/host1-example1-sitemap.xml
- https://host1.example.com/host1-example-ch-sitemap.xml
To submit sitemaps between sites hosted in a single location, we can use Search Console or robots.txt.
Specifically, with Search Console we must first have verified the ownership of all the sites we will add in the sitemap, and then create one or more sitemaps by including the URLs of all the sites we wish to cover. If we prefer, the guide says, we can include the sitemaps in a sitemap index file and work with that index. Using Google Search Console, we will submit either the sitemaps or the index file.
If we prefer to cross-submit sitemaps with robots.txt, we need to create one or more sitemaps for each individual site and, for each individual file, include only the URLs for that particular site. Next, we will upload all sitemaps to a single site over which we have control, e.g., https://sitemaps.example.com.
For each individual site, we need to check that the robots.txt file references the sitemap for that individual site. For example, if we have created a sitemap for https://example.com/ and are hosting the sitemap in https://sitemaps.example.com/sitemap-example-com.xml, we will reference the sitemap in the robots.txt file in https://example.com/robots.txt.
Best practices with sitemaps
Google’s documentation also gives some practical advice on the subject, echoing when indicated by the aforementioned sitemaps protocol, and in particular focuses on size limits, file location, and URLs included in sitemaps.
- Regarding limits, what was written earlier applies: all formats limit a single Sitemap to 50 MB (uncompressed) or 50,000 URLs. If we have a larger file or more URLs, we need to split the sitemap into several smaller sitemaps and optionally create a sitemap index file and send only this index to Google-or send multiple sitemaps and also the Sitemap Index file, especially if we want to monitor the search performance of each individual sitemap in Search Console.
- Google does not care about the order of URLs in the sitemap and the only limitation is size.
- Encoding and location of the sitemap file: the file must be encoded in UTF-8. We can host sitemaps anywhere on your site, but be aware that a sitemap only affects the descendants of the root directory: therefore, a sitemap published in the root of the site can affect all the files on the site, which is why this is the recommended location.
- Properties of referring URLs: we must use complete and absolute URLs in sitemaps. Google will crawl the URLs exactly as listed. For example, if the site is located at https://www.example.com/, we should not specify a URL such as /mypage.html (a relative URL), but the full and absolute URL: https://www.example.com/mypage.html.
- In the sitemap we will include the URLs we wish to display in Google search results. Usually, the search engine shows canonical URLs in its search results, and we can influence this decision with sitemaps. If we have different URLs for the mobile and desktop versions of a page, the guide recommends pointing to only one version in a sitemap or, alternatively, pointing to both URLs but noting the URLs to indicate the desktop and mobile versions.
- When we create a sitemap for the site, we tell search engines which URLs we prefer to show in the search results and then the canonical URLs: therefore, if we have the same content accessible with different URLs, we must choose the preferred URL by including it in the sitemap and excluding all URLs that lead to the same content.
Which pages to exclude from sitemaps
Broadening the discussion of recommended practices, we should not assume that the file is meant to contain all URLs on the site, and indeed there are some page types that should be excluded by default because they are not very useful.
As a general rule, only relevant URLs, those that offer added value to users and that we want to be visible in the Search should be included in the sitemap; all others should be excluded from the file (and this still does not ensure that they are “invisible,” unless we add a “no-index” tag), and this applies particularly to:
- Non-canonical pages
- Duplicate pages
- Pagination pages
- URLs with parameters
- Pages of site search results
- URLs created by filter options
- Archive pages
- Any redirects (3xx), missing pages (4xx) or server error pages (5xx)
- Pages blocked by robots.txt
- No-index pages
- Pages accessible from a lead gen form (PDF, etc.)
- Utility pages (login page, wish list/cart pages, etc.).
A guide to manage Sitemaps on Google Search Console
Google Search Console tools, and in particular the Sitemap Report, allow us to facilitate communication with search engine crawlers, as also explained by an episode of the webseries Google Search Console Training, in which Daniel Waisberg walks us through this topic.
In particular, the Developer Advocate reminds us that Google supports four modes of expanded syntax with which we can provide additional information, useful for describing files and content that are difficult to parse in order to improve their indexing: thus, we can describe a URL with images included or with a video, indicate the presence of alternative languages or geolocated versions with hreflang annotations, or (for news sites) use a particular variant that allows us to indicate the most recent updates.
Google and Sitemap
“If I don’t have a sitemap, can Google still find all the pages on my site?” The Search Advocate also answers this frequently asked question, explaining that a sitemap may not be necessary if we have a relatively small site with appropriate internal linking between pages, because Googlebot should be able to discover the content without problems. Also, we may not need this file if we have few multimedia files (videos and images) or news pages that we intend to show in the appropriate search results.
On the contrary, in certain cases a sitemap is useful and necessary to help Google decide what and when to crawl your site:
- If we have a very large site, with the file we can prioritize the URLs to be crawled.
- If the pages are isolated or not well connected.
- If we have a new site (and therefore little linked from external sites) or one with rapidly changing content.
- If the site includes a lot of rich media content (video, images) or is displayed in Google News.
In any case, the Googler reminds us, using a sitemap does not guarantee that all pages will be crawled and indexed, although in most cases providing this file to search engine bots can give us benefits (and certainly does not give disadvantages). Also, sitemaps do not replace normal crawling, and URLs not included in the file are not excluded from crawling.
How to make a sitemap
Ideally, the CMS running the site can make sitemap files automatically, using plugins or extensions (and we recall the project to integrate default sitemaps into WordPress), and Google itself suggests finding a way to create sitemaps automatically rather than manually.
There are two limits to sitemaps, which cannot exceed a maximum number of URLs (50 thousand per file) and a maximum size (50 MB uncompressed), but if we need more space we can create multiple sitemaps. We can also submit all these sitemaps together in the form of a Sitemap Index file.

The Search Console Sitemap Report
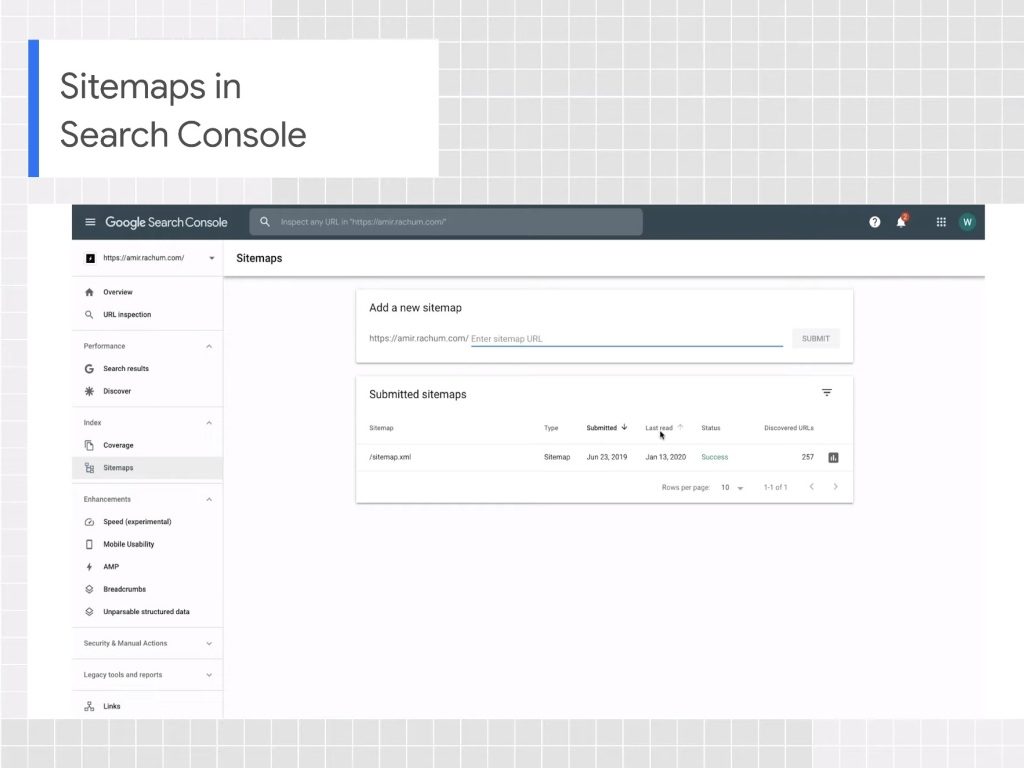
To keep track of these resources we can use the Sitemap Report in Search Console, one of the most useful webmaster tools, which is used to submit a new sitemap to Google for ownership, view the submission history, view any errors found during the analysis, and remove files that are no longer relevant. This action removes the sitemap only from the Search Console and not from Google’s memory: to delete a sitemap we have to remove it from our site and provide a 404; after several attempts, Googlebot will stop following that page and will no longer update the sitemap.
The tool allows us to manage all sitemaps on the site, as long as they have been submitted through Search Console, and therefore does not show files discovered through robots.txt or other methods (which can still be submitted in GSC even if already detected).
The sitemap report contains information about all submitted files, and specifically the URL of the file relative to the root of the property, the type or format (such as XML, text, RSS, or atom), the date of submission, the date of the last Google read, the crawl status (of the submission or crawl), and the number of URLs detected.
How to read sitemap’s status
The report indicates three possible states of sitemap submission or crawling.
- Success is the ideal situation, because it means that the file has been uploaded and processed correctly and without errors, and all URLs will be queued for crawling.
- Has errors means that the sitemap could be parsed but has one or more errors; URLs that could possibly be parsed will be queued for crawling. By clicking on the report table, we can find out more details about the problems and get pointers to corrective actions.
- Couldn’t fetch, if some reason prevented the file from being recovered. To find out the cause we need to do a real-time test on the sitemap with the URL Checker tool.
XML sitemap, 3 steps to improve SEO
Despite all the precautions we can use, there are still situations in which the sitemap presents critical issues that can become a hindrance to organic performance; to avoid boredom and problems, there are three basic steps to assess, which can also to improve SEO, as suggested by an article published by searchengineland that points us to a quick checklist to follow for our sitemaps provided to search engine crawlers, useful to avoid errors such as the absence of important URLs (which could potentially therefore not be indexed) or the inclusion of wrong URLs.
Verify the presence of priority and relevant URLs
The first step is to verify that we have included in the sitemap all the key URLs of the site, that is, those that represent the cornerstone of our online strategy.
An XML sitemap can be static, thus representing a snapshot of the Web site at the time of creation (and therefore not updated later) or, more effectively, dynamic. The dynamic sitemap is preferable because it updates automatically, but the settings must be checked to ensure that we are not excluding sections or URLs central to the site.
To check that relevant pages are all included in the sitemap we can also do a simple search with Google’s site: command, so we can immediately find out if our key URLs have been properly indexed. A more direct method is to use some crawling tools with which to compare the pages actually indexed and those included in the sitemap submitted to the search engine.
Checking if there are URLs to remove
Of completely opposite sign is the second check: not all URLs should be included in the XML sitemap and it is indeed better to avoid including addresses that have certain characteristics, such as
- URLs with HTTP status codes 4xx / 3xx / 5xx.
- Canonicalized URLs.
- URLs blocked by txt.
- URLs with noindex.
- Paging URLs.
- Orphan URLs
An XML sitemap should normally contain only indexable URLs that are responsive with a 200 status code and are linked within the Web site. Including other page types, such as those shown, could contribute to worse crawl budgets and potentially cause problems, such as indexing orphan URLs.
Scanning the sitemap with crawling tools allows you to highlight if there are any resources that are incorrectly included and, therefore, take action to remove them.
Making sure that Google has indexed all the URLs in the XML sitemap
The last step is about how Google has transposed our sitemap: to get a better idea of which URLs have actually been indexed, we need to submit the sitemap in Search Console and use the aforementioned Sitemap report and index coverage status report, which give us insights into the search engine’s coverage.
In particular, the index coverage report allows us to check the Errors section (which highlights problems with sitemaps as URLs that generate a 404 error) and the Excluded URLs section (pages that have not been indexed and do not appear in Google), including the reasons for this absence.
If these are useful pages – not duplicated or blocked – there may be a quality problem, such as the famous thin content, or an incorrect status code, particularly for pages that have been crawled but are not currently indexed (Google has chosen not to include the page in the Index for now) and for pages that have been detected but not indexed (Google tried crawling, but the site was overloaded), and then it is time to intervene with appropriate onsite optimizations.
Sitemap, 10 errors to avoid
While these are some of the priority checks to be made to verify that the sitemap we have created and submitted to Google is effective and valid, it is then good to also have an overview of the possible errors present in sitemaps, so that we can more easily understand if we have run into a similar situation in our process of creating the file.
This, specifically, is a list of the 10 sitemap errors that can impair a site’s performance and negatively affect results in organic search.
1. Choosing the wrong format for the sitemap
The most common mistake with the sitemap concerns the format: Google supports different types of files for inclusion in Search Console, expecting the use of the standard Sitemap protocol in all formats and not providing (at the moment) the <priority> attribute in sitemaps. Accepted formats are XML, the most widely used, and then again .txt (text file, valid only if the sitemap contains web page URLs and not other resources), RSS 2.0 feeds, mRSS and Atom 1.0, but Google also supports expanded Sitemap syntax for certain media content.
2. Using unsupported encodings and characters
 A similar, but more specific, inaccuracy concerns the method of encoding characters used to generate Sitemap files: the required standard is UTF-8 encoding, which can generally be applied when saving the file, and the Google Guide explains that “all data values (including URLs) must use escape codes” for certain critical characters (as seen in the image on the page).
A similar, but more specific, inaccuracy concerns the method of encoding characters used to generate Sitemap files: the required standard is UTF-8 encoding, which can generally be applied when saving the file, and the Google Guide explains that “all data values (including URLs) must use escape codes” for certain critical characters (as seen in the image on the page).
In detail, a map can only contain ASCII characters, while uppercase ASCII characters and special control codes and characters (e.g., asterisk * and curly brackets {}) are not supported. Using these characters in the Sitemap URL will generate an error when adding the Sitemap.
3. Exceeding the maximum file size
The third problem is common with very large sites with hundreds of thousands of pages and tons of content: the maximum size allowed for a sitemap file is 50,000 URLs and 50 MB in uncompressed format. When our file exceeds these limits, we need to split the sitemap into smaller sitemaps, then create a Sitemap Index file where the other resources are listed and send only this file to Google. This step is to avoid “overloading the server if Google requests the Sitemap often.”
4. Including multiple versions of URLs
This is especially an inconvenience with sites that have not perfectly completed the migration from http to https protocol, and therefore have pages that have both versions: if you include both URLs in the Sitemap, the crawler may perform an incomplete and imperfect crawl of the site.
5. Include incomplete, relative, or inconsistent URLs
It is then critical to properly communicate to search engine spiders what is the precise link path to follow, because Googlebot and others crawl URLs exactly as they are given. Therefore, including relative, non-uniform or incomplete URLs in the sitemap file is a serious mistake, because it generates invalid links. In practical terms, this means that you have to include the protocol, but also (if required by the web server) the final slash: the address https://www.esempio.it/ thus represents a valid URL for a Sitemap, while www.esempio.it, https://example.com/ (without using the www) or ./mypage.html are not.
6. Including session IDs in the Sitemap
The sixth point is quite specific: it is the sitemaps project FAQ page that makes it clear that “including session IDs in URLs may result in incomplete and redundant crawling of the site.” So, including session IDs of URLs in your sitemap can result in increased duplicate crawling of those links.
7. Mistaking date entry
We know that search engines, and particularly Google, are placing increasing emphasis on date insertion in web pages, but handling the “time factor” can sometimes be problematic for Sitemap insertion.
The valid process for inserting dates and times in the Sitemaps protocol is to use the W3C Datetime encoding, which allows all time variables to be handled, including approximate periodic updates if relevant. Accepted formats are, for example, year-month-day (2019-04-28) or, specifying the time, 2019-04-28T18:00:15+00:00, also indicating the reference time zone.
These parameters can avoid scanning URLs that have not changed, and thus reduce bandwidth and CPU requirements for web servers.
8. Do not include mandatory XML attributes or tags.
This is one of the errors often flagged by the Search Console Sitemap report: mandatory XML attributes or mandatory XML tags may be missing in one or more entries in some files. Inversely, it is similarly wrong to insert duplicate tags in Sitemap: in all cases, action must be taken to correct the problem and attribute values, and then resubmit the Sitemap.
9. Creating an empty sitemap
Let’s close with two types of errors that are as serious as they are branded, which basically undermine everything we have said about sitemaps that is positive and useful. The first is really a beginner’s one, which is to save an empty file that does not contain any URLs and submit it to Search Console: needless to add more.
10. Making a Sitemap not accessible to Google
The other and final problem concerns a fundamental concept for those working online and trying to compete on search engines: to fulfill its task, the sitemap “must be accessible to and not be blocked by any access requirements,” Google writes, so all the blocks and limitations that are encountered are a hindrance to the process.
An example is including URLs in the file that are blocked by the robots.txt file, which then does not allow Googlebot to access some content, which otherwise cannot be crawled normally. The crawler may also have difficulty following certain URLs, especially if they contain too many redirects: the suggestion in this case is to “replace the redirect in your sitemaps with the URLs that should actually be crawled” or, in case such a redirect is permanent, to use precisely a permanent redirect, as explained in Google’s guidelines.