
Mobile First Indexing, how to solve the main problems
It is inevitably one of the hottest topics of SEO and it is Google itself to keep high the attention on mobile-first indexing that, as reiterated again in recent weeks, will be final by March 2021. The theme was the focus of Martin Splitt’s intervention in the Webmaster Conference Lightning Talks series, in which are address the possible problems that can be encountered and the best practices to use so to prepare the site to this switch.
What is the mobile-first indexing, the new Googlebot scan
Inevitably, the video starts from the definition of mobile-first indexing and the operation of indexing performed by Google.
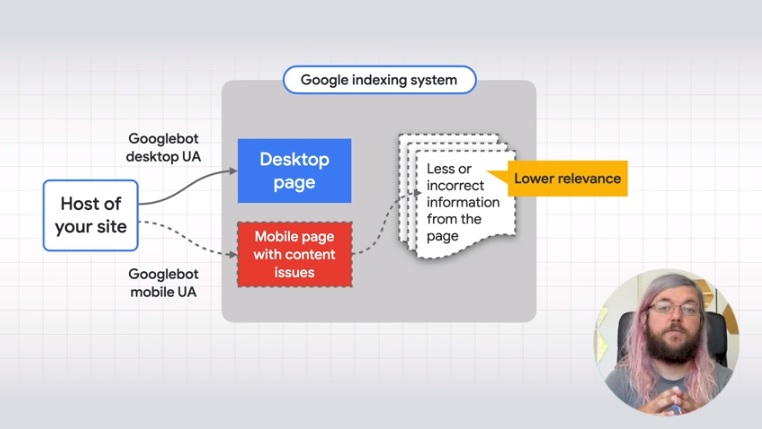
First of all, Googlebot crawls URLs from the site with the desktop and mobile user agent. With the old desktop-first indexing system, the indexing system gets page information from the page content in desktop version. Then, if the algorithm believes that it contains information of sufficient relevance to user queries, the page will be shown in search results.
With mobile indexing, the indexing system will search for page information in the mobile version instead of on the desktop one.
The challenges and possible issues for sites
Having clarified the (basic) difference between desktop-first and mobile-first indexing, Splitt moves on in making an overview of the possible challenges facing site owners and webmasters compared to the indexing system for mobile devices.
There may be errors during crawling, for instance, or problems with the contents of the page being scanned: let’s see in detail what can be done in these cases and how to intervene.
Case 1, crawling issues
A frequent problem concerns possible errors in crawling with Googlebot mobile: our server may treat the request based on the user agent differently or there may be other problems related to a request to the mobile pages.
When these situations occur, Google will be able to derive little (or even none) information from our pages, and therefore obviously will not have enough data to decide to show the page in search results, with the result that it will be excluded from SERPs.
Case 2, problems with mobile contents
Another problematic case is when Google notices that our mobile page has content issues: the bot will get less information from the page, or even get the wrong ones, and thus cannot effectively determine its relevance to the queries of users.
This occurs especially if a site has separate mobile pages, which offer different contents than the desktop version.
Recognizing the main mobile crawling issues
Both of these situations prevent Google from correctly serving the site “when it is enabled for mobile-first indexing”, which is “something you probably want to avoid”, jokes the Developer Advocate in the video.
In order not to run into these problems and solve them, Splitt offers some useful guidance and elements to evaluate to ensure that there are no issues while scanning pages for mobile devices. In particular, we MUST NOT:
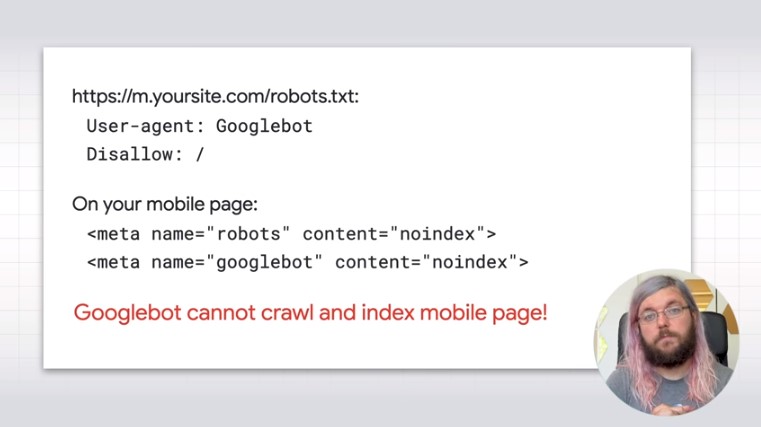
- Use a Disallow directive in the txt file for mobile pages.
- Use the noindex meta tag on mobile pages.
These two errors do not allow Googlebot to scan and index mobile pages (as seen in the image).
- Use a disallow directive on mobile CSS files with a rule in robots.txt.
- Use the nofollow meta tag on internal links.
These two errors do not allow Googlebot to scan mobile resources.

In general, if we give Googlebot access to resources on the desktop page we should do the same in the mobile version, as well, or else the bot will not be able to fully analyze and understand the mobile page.
In addition to these best practices on robots.txt directives, noindex and nofollow tags, site owners should also check their server’s scanning capability: ideally, a server should be able to handle the same amount of desktop and mobile scans.
Detecting content issues of mobile pages
Setting up the mobile page content correctly is as important as checking that the mobile crawler settings are correct. Google’s general suggestion is to make sure you serve identical primary content in both desktop and mobile versions, but in some cases this may be different.
Different contents between mobile and desktop
For example, says Splitt, we may have a desktop page that comes with various images and some text, while in the mobile version we decide to present only two images and very little text: users must click on the + (plus) button to load the remaining part of the page.
However, Googlebot will not click the button, and thus any information not immediately uploaded will be invisible to Google. Therefore – also as a general note – the Googler says that if we intend to have less content on the mobile page, we must be aware that Google may not be able to serve our site as well as before the mobile-first indexing, just because it gets (we give) less information than desktop indexing.
Headings management
Headings are important for Googlebot to understand our page: using classic tags is a “good example of header”, while it is wrong to use <div> commands.
In this case, regardless of its class, Googlebot will treat this portion of text as if it were a normal text and not a title; this will then affect Googlebot’s understanding of the page.

The practical advice is therefore to refer to semantic header tags on our mobile pages.
Management of images and videos
“If you care about the traffic generated by images and videos, you have to do some extra checks on those resources“, Splitt tells us.
First of all, it is important to edit the creation of the alt text to define an image and not to leave the field empty or insert too generic terms, because such practice can cause a bad experience for some users, that they would have no way of understanding the topic of the image when they can’t visualize it. As in the previous case, we cannot insert the attributes in the image in a <div> field because Googlebot cannot read and index the resources in this way, but therefore only use semantic image tags.

In addition to these classic tips for the SEO management of images, it is also important for mobile pages to edit the location of media resources: if a video is in an easy-to-see position in the desktop version, the presence of an ad could move it to the mobile page, forcing users to scroll very low to finally see the content and generating, once again, a bad user experience.
Checking the invisible parts of pages
The last aspect to pay attention to is the handling of the invisible parts of the page – of course, Splitt does not refer to black hat SEO tactics and hidden contents! – which do not affect the user experience, but may affect the way Googlebot understands the contents and topics covered.
An example of an invisible part of the page are the structured data: the best practice is to keep the same markups on desktops and mobile pages.
Another example are the meta descriptions, and Google invites you not to forget to add this information to our mobile pages, because meta descriptions “are very important for Googlebot too”.
