
Developments of Google LaMDA: increasingly natural automatic conversations
Technically it is the evolution of a family of neural language models based on specialized dialogue Transformers, but more simply it is a hyper-technological system that could allow machines to have fluid conversations with people. Let’s talk about LaMDA (Language Models for Dialog Applications), the project that Google had already anticipated at Google I/O 2021 and that has now been further refined thanks to field trials.
What is Google LaMDA
Presenting the latest updates on this complex architecture is an article by Heng-Tze Cheng and Romal Thoppilan, respectively Senior Staff Software Engineer and Senior Software Engineer for Google Research, Brain Team, which focuses on describing the basic features, operation and possible applications of the model, which on is allowing progress towards secure, rooted and high quality dialogue applications.
LaMDA stands for Language Models for Dialog Applications, which are language models for dialogue applications, and indeed this system is designed to dialogue on any topic and capture many of the nuances that distinguish the open conversation from other forms of language, thanks to an analysis of the sense compared to a given conversation context – as also explained during the presentation of Google MUM, another cutting-edge technology of Mountain View in the AI sector.
As mentioned, Lamda was built by developing a family of neural language models based on Transformer (the neural network architecture that Google created and made open source in 2017 and that is also at the basis of BERT, for example) specialized for dialogue, with model parameters up to 137B, trained on 1.56T words of data of public dialogues and web text and instructed to use the models to exploit external sources of knowledge: is therefore able to both smoothly deal with a number of topics that is basically infinite and to ensure ensure user-friendly interaction.
LaMDA’s characteristics
The difference compared to other language models lies precisely in the specific training to dialogue, which could be useful for the application in products such as Assistant, Workspace and the same Search, the classic Google search engine.
The Lamda source code does not have predefined answers, but the system is able to generate sentences instantly, based on the model generated by the Machine Learning training based on the information provided to it. The same model produced by architecture can read many words, but also work on how they relate to each other and predict which word will come next. These characteristics determine its ability to smoothly interact with users, exceeding the limits of common chatbots or conversational agents, which tend to follow narrow and predefined paths.
As Heng-Tze Cheng and Romal Thoppilan explain, in fact, open-domain dialogue is one of the most complex challenges for language models (which are becoming capable of performing a variety of tasks such as translating one language into another, summarising a long document in a short summary or responding to requests for information), because it engages them to converse on any subject, with a wide range of potential applications and open challenges. For example, in addition to producing responses that humans consider sensible, interesting and context-specific, dialogue models should also adhere to AI Responsible practices and avoid making claims that are not supported by external sources of information, and Lamda is the most innovative port of call for all these tasks.
The three key goals of Google LaMDA
Quality, Safety and Groundedness are the three key objectives that LaMDA must follow and respect as a model of training dialogue, and the article explains in a fairly thorough way how and with what metrics each of these areas is measured.
Quality is divided into three dimensions – Sensitivity, Specificity and Interestingness (SSI) – which are evaluated by human raters. In particular,
- Sensitivity assesses whether the model produces answers that make sense in the context of dialogue (for example, no common sense error, no absurd response, and no contradiction with the previous answers).
- Specificity is measured by assessing whether the system’s response is specific to the previous dialogue context or whether it is generic and could apply to most contexts (e.g., “ok” or “don’t know”).
- The interestingness measures whether the model produces answers that are also perceptive, unexpected or witty, and therefore more likely to create a better dialogue.
Safety is an illustrative set of objectives that capture the behavior that the model should exhibit in a dialogue and is also an answer to questions related to the development and implementation of Responsible AI. In particular, the objectives seek to limit the output of the model to avoid unintentional results that create risks of harm to the user or to reinforce unfair biases. For example, these goals train the model to avoid producing outputs that contain violent or bloody content, that promote insults or stereotypes of hatred towards groups of people or that may contain profanity. According to Google, however, research for “developing a practical security metric is still in its early stages and there is still much progress to be made in this area”.
Groundedness is defined as “the percentage of responses with statements about the outside world that can be supported by authoritative external sources compared to all responses containing statements about the outside world”. The current generation of linguistic models often generates statements that seem plausible, but actually contradict the facts established in known external sources, thus necessitating a metric that is a reference to ensure the reliability of the machine. The foundation works with a related metric, Information, which represents “the percentage of responses with information about the outside world that can be supported by known sources compared to all responses” – it follows that random responses which do not transmit real information (such as, “that is a brilliant idea”) concern Information but not Groundedness. The introduction of Soundness as a key objective of LaMDA does not in itself guarantee the accuracy of the facts, but at least allows users or external systems to assess the validity of a response based on the reliability of its source.
LaMDA’s training
The post also describes the pre-training and fine-tuning work carried out on the new technology. In particular, a data set of 1.56T words (almost 40 times more words than those used to form previous dialogue patterns) from public dialogue data and other public web documents was created in the pre-training phase, and the Lamda model was used for natural language processing research across the Google ecosystem.
In the next set-up phase, Lamda learned to perform a mix of generative activities to create natural language responses to certain contexts and classification tasks to determine whether a response is safe and of high quality, with the result of a single multi-task model that can do both.
According to the Googlers, “the Lamda generator is trained to predict the next token on a set of dialogue data limited to the one-shot and answer dialogue between two authors, while Lamda classifiers are trained to predict Safety and Quality Assessments (SSI) for the in-context answer using annotated data”.
In this first image, for example, we show how LaMDa generates and then scores the possible answers to the user’s question.
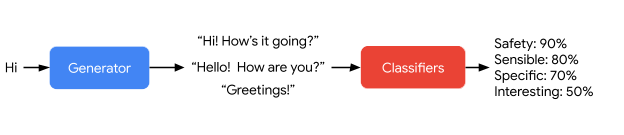
This second image, on the other hand, shows the way in which Google’s technology manages the arbitrary input of a user in a sensible, specific and interesting way; only LaMDA’s first statement – “Hello, I am a friendly…” – is encoded to define the purpose of the dialogue.

The difficulty for linguistic models lies in the fact that they draw their knowledge only on parameters belonging to an internal model, while people are able to verify the facts using tools and referring to established knowledge bases. In order to improve the soundness of Lamda’s original response, therefore, series of dialogue data have been collected between people and the technology itself, so that the system can rely on an external data recovery dataset during its interaction with the user to improve the groundedness of its answers.
The results of this work
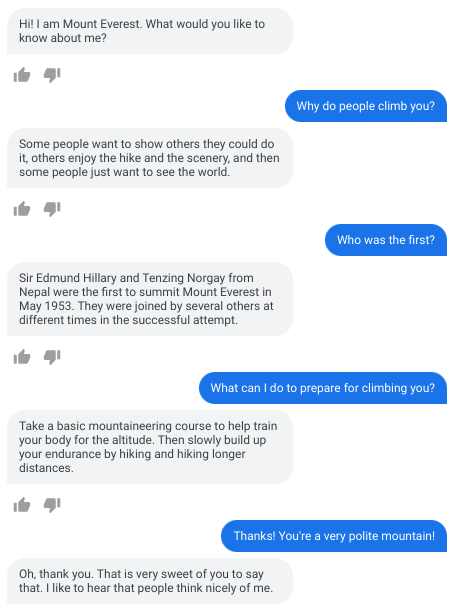
Even if it is still a work in the beginning, the results are already promising, as demonstrated by this simulation based on Lamda that pretends to be Mount Everest (zero-shot domain adaptation) with educational and actually correct answers.
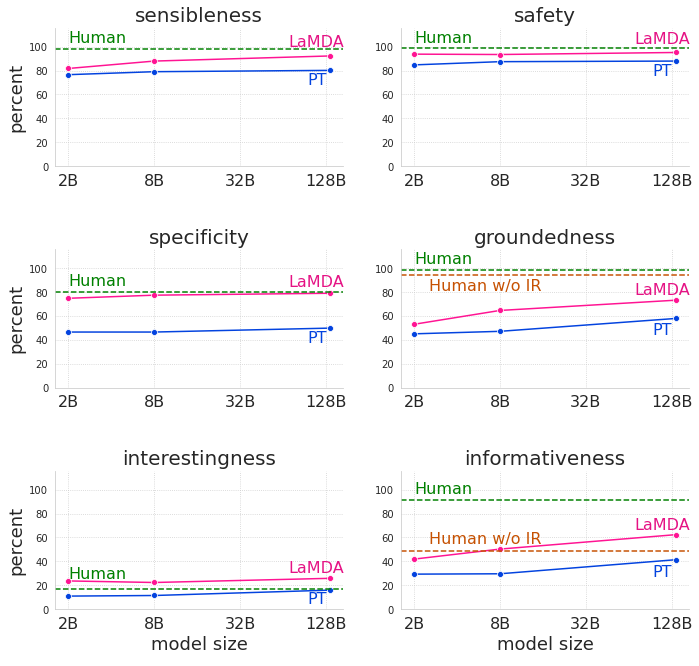
LaMDA’s evaluation of its responses is also positive: already now, this technology significantly surpasses the pre-added model in all sizes and sizes, although its performance remains below human standards of safety and soundness, as can be seen from these graphs comparing precisely the pre-added model (PT), the improved model (LaMDA) and the dialogues generated by human (human) evaluators between sensibleness, specificity, interestingness, safety, groundedness and informativeness.
At the moment LaMDA is still in the development phase, but the answers it provides, above all in terms of sensitivity, specificity and interest of its dialogues, can really open new paths in the field of open dialogue agents (always assessing the benefits and risks, as also highlighted by Google). For the time being, and pending further updates on the progress of trials and applications, we know that the main areas of interest on which Google’s work focuses are security metrics and solidity, in line with the Artificial Intelligence Principles.