
Crawl budget: what it is, why it matters to SEO and how to optimize the value
It is the parameter that identifies the time and resources Google intends to devote to a website through Googlebot scans, a value that is not unique and numerically definable, as clarified repeatedly by the company’s official sources, although we can still take action to optimize it. Today let’s talk about crawl budget, a topic that is becoming increasingly central to improving site performance, and the various strategies for optimizing this parameter and refining the attention the crawler can devote to content and pages prioritized for us.
What is the crawl budget
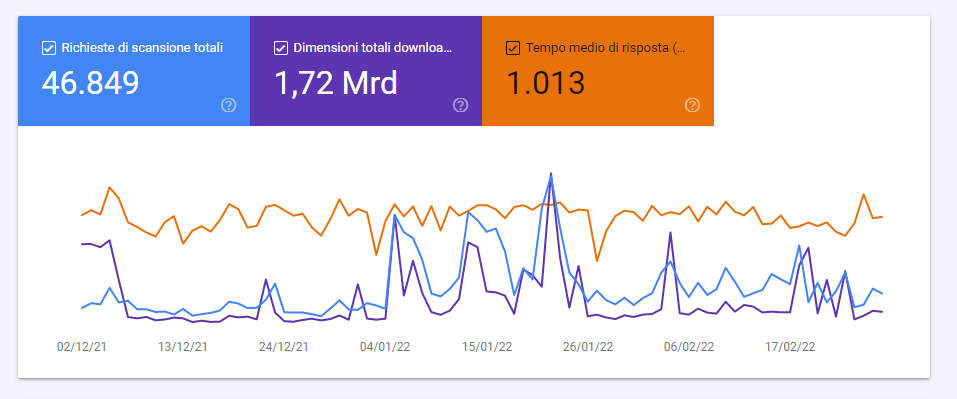
Does Google like my website? This is the question everyone who has a website they want to rank on search engines should ask themselves. There are several methods to figure out whether Big G actually likes a site, for example through the data within Google Search Console and the Crawl Stats report, a tool that allows us to know precisely the crawl statistics of the last 90 days and to find out how much time the search engine spends on our site.
Put even more simply, in this way we can find out what is the crawl budget that Big G has dedicated to us, the amount of time and resources that Google devotes to crawling a site.
The definition of crawl budget
The crawl budget is a parameter, or rather a value, that Google assigns to our site. It is basically just like a budget that Googlebot has to crawl the pages of our site. Through Search Console it is possible to understand how many files, pages and images are downloaded and scanned every day by the search engine.
It is easy to see that the higher this value, the more importance we have for the search engine itself. Basically, if Google scans and downloads so many pages every day, it means that it wants our content because it is considered of quality and value for the composition of its SERPs.
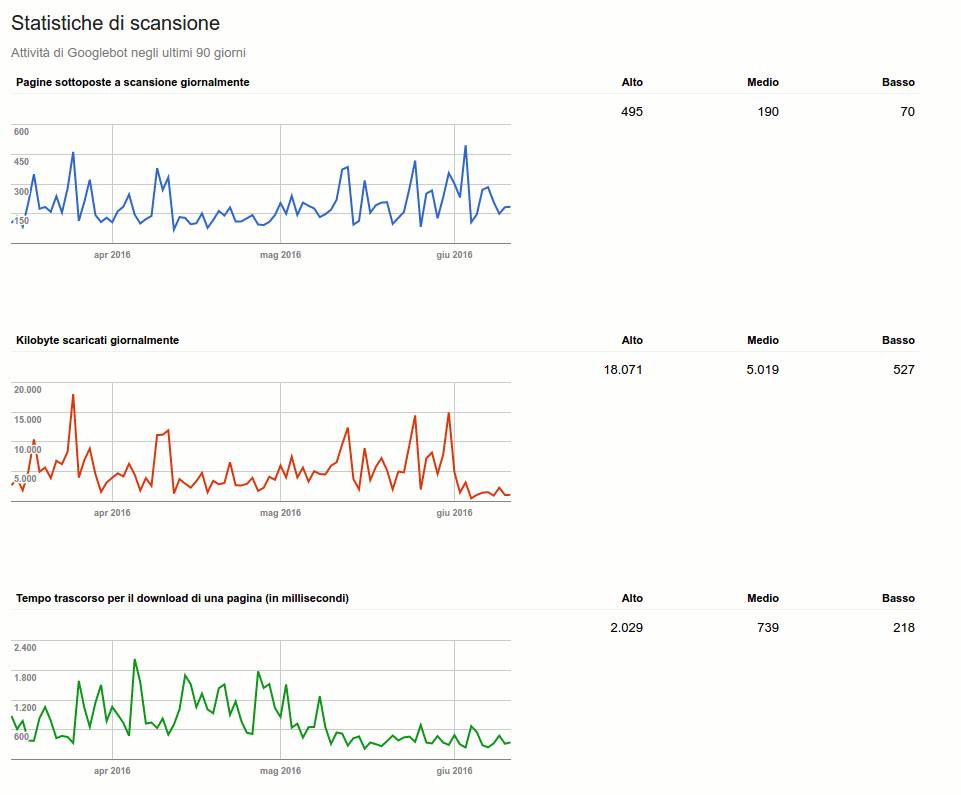
Mainly, there are definitely two values to consider, namely the number of pages Google scans each day and the time it takes to do so. Let’s go through this in detail:
- Pages crawled daily: the ideal value is to have a total number of pages crawled higher than the number of pages on the website, but even a tie (pages crawled equal to the number of pages on the website) is more than fine.
- Elapsed time for downloading: this mainly indicates the time it takes Googlebot to scan our pages, we should keep this value low by going to increase the speed of our website. This will also affect the number of kb downloaded by the search engine during scans, i.e. how easily (and quickly) Google can “download” the pages of a website.
The two images posted here also show the evolution of this domain: values that in 2016 (top screen) signaled average activity today are instead indicative of low demand.
What is the crawl budget for Google
Simply put, the crawl budget is the number of URLs that Googlebot can (depending on the speed of the site) and wants (depending on the request of users) to scan. Conceptually, then, it is the balanced frequency between Googlebot’s attempts to not overload the server and Google’s overall desire to scan the domain.
To take care of this aspect could allow to increase the speed with which the robots of the search engines visit site pages; the greater it is the frequency of these passages, the faster the index will detect the updates of the pages. Therefore, a higher value of crawl budget optimization can potentially help keep popular contents up to date and prevent older content from becoming obsolete.
As the new official guide to this issue, last updated at the end of February 2023, says, the crawl budget was created in response to a problem: the Web is a virtually infinite space, and exploring and indexing every available URL is far beyond Google’s capabilities, which is why the amount of time Googlebot can spend crawling a single site is limited – that is, the crawl budget parameter. Furthermore, not all crawled items on the site will necessarily be indexed: each page must be evaluated, merged, and verified to determine whether it will be indexed after crawling.
How the crawl budget is measured
The crawl budget can then be defined as the number of URLs that Googlebot can and wants to crawl, and it determines the number of pages that search engines scan during a search session for indexing. In technical terms, its value depends on the crawl capacity limit (crawl rate) and crawl demand.
What are crawl rate and crawl demand
The expression crawl rate refers to the number of requests per second that a spider makes to a site and the time that passes between fetches, while crawl demand is the frequency with which such bots crawl. Therefore, according to Google’s official advice, the sites that need to be most careful about these aspects are those that are larger and have multiple pages or those that have auto-generated pages based on URL parameters.
The limits of the crawl rate for a site
Going deeper with the explanations, Googlebot’s job is to crawl each site without overloading its servers, and so it calculates this crawl capacity limit represented by the maximum number of simultaneous connections it can use to crawl a site and the delay between fetches, so that it still provides coverage of all important content without overloading its servers.
The limit on crawl rate or crawl capacity is first and foremost out of respect for the site: Googlebot will try never to worsen the user experience due to fetching overload. So, there is for each site a maximum number of simultaneous parallel connections that Googlebot can use to crawl, and the crawl rate can increase or decrease based:
- To the health of the site and the server. In short, if a site responds quickly, the limit goes up and Google uses more connections for crawling; if crawling is slow or server errors occur, the limit goes down.
- To the limit set by the owner in Search Console, remembering that setting higher limits does not automatically increase crawl frequency
- To Google’s crawl limits, which as mentioned has considerable, but not unlimited, resources, and therefore must prioritize them to optimize their use.
Popularity and staleness determine Google’s crawl demand
Crawl demand, on the other hand, is related to popularity: URLs that are most popular on the Web tend to be crawled more frequently to keep them “fresher” in Google’s Index. In addition, the search engine’s systems try to prevent staleness, that is, URLs from becoming obsolete in the index.
Generally, the aforementioned guide specifies, Google spends as much time as necessary crawling a site based on site size, update frequency, page quality, and relevance, commensurate with other sites. Therefore, the factors that play a significant role in determining crawl demand are as follows:
- Perceived inventory: in the absence of any indication from the site, Googlebot will try to crawl all or most of the known URLs on the site itself. If it finds a large number of duplicate URLs or pages that do not need to be crawled because they are removed, unimportant, or otherwise, Google may take longer than it should to crawl them. This is the factor we can keep most under control.
- Popularity: the most popular URLs on the Internet tend to be crawled more often to keep them constantly updated in the Index.
- Missing update: systems scan documents frequently enough to detect changes.
- Site-level events, such as site relocation, can generate increased demand for scanning to re-index content based on new URLs.
In summary, then, Google determines the amount of crawling resources to allocate to each site based on factors such as popularity, user value, uniqueness, and publishing capacity; any URLs that Googlebot crawls are counted for budget purposes, including alternate URLs, such as AMP or hreflang, embedded content, such as CSS and JavaScript, and XHR retrievals, which can then consume a site’s crawling budget. Moreover, even if the crawl capacity limit is not reached, Googlebot’s crawl rate may be lower if the site’s crawl demand is low.
The only two ways to increase the crawl budget are to increase the publication capacity for crawls and, most importantly, to increase the value of the site content to searchers.
Why the crawl budget is important for SEO
When optimized, crawl budget allows webmasters to prioritize the pages that need to be crawled and indexed first, in case crawlers can scan each path. Conversely, wasting server resources on pages that do not generate results and do not actually produce value produces a negative effect and risks missing out on a site’s quality content.
How to increase the crawl budget
But is there a way to go about increasing the crawl budget that Google itself makes available to us? The answer is yes, and it only takes a few steps.
One of the methods to increase the crawl budget is definitely to increase the trust of the site. As we know well, among Google’s ranking factors there are definitely links: if a site is linked it means that it is “recommended” and consequently the search engine interprets it just as a recommendation and, therefore, goes to consider that content.
Also affecting the crawl budget is how often the site is updated, that is, how much new content is created and how often. Basically, if Google comes to a website and discovers new pages every day what it will do is reduce the crawl time of the website itself. A concrete example: usually, a news site that publishes 30 articles a day will have a shorter crawl time than a blog that publishes one article a day.
Another way to increase the crawl budget is definitely the speed of the website, that is, the response of the server in serving the requested page to Googlebot. Finally, we can also use the robots.txt file to prevent Googlebot from going to crawl those pages that have the “noindex” tag or the “canonical” tag inside, so that it does not have to see and crawl them anyway to know whether it can index them or not; by using the robots.txt intelligently, then, we can allow the crawler to focus on the best pages on the website.
How to enhance the crawl budget
One of the most immediate ways to optimize the crawl budget is to limit the amount of low-value URLs present on a website, which can – as mentioned – take away valuable time and resources from the scan of the most important pages of a site.
Low-value pages include those with duplicate content, soft error pages, faceted navigation and session identifiers, and then again pages compromised by hacking, endless spaces and proxies and obviously low-quality content and spam. A first work that can be done is therefore to verify the presence of these problems on the site, also checking the reports on the scanning errors in Search Console and reducing to the minimum the errors of the server.
Google’s tips for maximizing crawling efficiency
Before we find out what are the SEO side tips, we can read what are the best practices for maximizing crawl efficiency that come directly from Google.
As repeated often, there are three categories of sites in particular that should be concerned about the crawl budget (the figures given are only a rough estimate and are not meant to be exact thresholds):
- Large sites (over one million unique pages) with content that changes with some frequency (once a week).
- Medium to large sites (over 10,000 unique pages) with content that changes very frequently (every day).
- Sites with a substantial portion of total URLs classified by Search Console as Detected, but not currently indexed.
But of course all other sites can benefit and optimization insights from these interventions as well.
- Manage your inventory of URLs, using the appropriate tools to tell Google which pages should or should not be crawled. If Google spends too much time crawling URLs that are unsuitable for indexing, Googlebot may decide that it is not worth examining the rest of the site (let alone increasing the budget to do so). Specifically, we can:
– Merge duplicate content, to focus crawling on unique content instead of unique URLs.
– Block URL crawling using robots.txt. file, so as to reduce the likelihood of indexing URLs that we do not wish to be displayed in Search results, but which refer to pages that are important to users, and therefore to be kept intact. An example are continuously scrolling pages that duplicate information on related pages or differently ordered versions of the same page.
In this regard, the guide urges not to use the noindex tag, as Google will still execute its request, although it will then drop the page as soon as it detects a meta tag or noindex header in the HTTP response, wasting scanning time. Likewise, we should not use the robots.txt file to temporarily reallocate some crawl budget for other pages, but only to block pages or resources that we do not want crawled. Google will not transfer the newly available crawl budget to other pages unless it is already reaching the site’s publishing limit.
- Returning a 404 or 410 status code for removed pages Google will not remove a known URL, but a 404 status code clearly signals to avoid rescanning that given URL; blocked URLs will continue to remain in the crawl queue, although they will only be rescanned with the removal of the block.
- Eliminate soft 404 errors. Soft 404 pages will continue to be crawled and negatively impact the budget.
- Keep sitemaps up to date, including all content we want crawled. If the site includes updated content, we must include the <lastmod> tag.
- Avoid long redirect chains, which have a negative effect on crawling.
- Check that pages load efficiently: if Google can load and display pages faster, it may be able to read more content on the site.
- Monitor site crawling, checking to see if the site has experienced availability problems during crawling and looking for ways to make it more efficient.
How to improve the efficiency of a site’s crawl
The search engine’s guide also gives us other valuable pointers to try to manage the crawl budget efficiently. In particular, there are a number of interventions that allow us to increase the loading speed of the page and the resources on it.
As mentioned, Google’s crawling is limited by factors such as bandwidth, time and availability of Googlebot instances: the faster the site’s response, the more pages are likely to be crawled. Fundamentally, however, Google would only want to crawl (or at any rate prioritize) high-quality content, so speeding up the loading of low-quality pages does not induce Googlebot to extend the site crawl and increase the crawl budget, which might happen instead if we let Google know that it can detect high-quality content. Translated into practical terms, we can optimize pages and resources for crawling in this way:
- Prevent Googlebot from loading large but unimportant resources using the robots.txt file, blocking only non-critical resources, i.e., resources that are not important for understanding the meaning of the page (such as images for decorative purposes).
- Ensure that pages load quickly.
- Avoid long redirect chains, which have a negative effect on crawling.
- Check the response time to server requests and the time it takes to render pages, including the loading and execution time of embedded resources, such as images and scripts, which are all important, paying attention to voluminous or slow resources needed for indexing.
Again from a technical perspective, a straightforward tip is to specify content changes with HTTP status codes, because Google generally supports If-Modified-Since and If-None-Match HTTP request headers for crawling. Google’s crawlers do not send headers with all crawl attempts, but it depends on the use case of the request: when crawlers send the If-Modified-Since header, the value of the header is equivalent to the date and time of the last content crawl, based on which the server might choose to return an HTTP 304 (Not Modified) status code without a response body, prompting Google to reuse the version of the content that was last crawled. If the content is after the date specified by the crawler in the If-Modified-Since header, the server may return an HTTP 200 (OK) status code with the response body. Regardless of the request headers, if the contents have not changed since the last time Googlebot visited the URL, however, we can send an HTTP 304 (Not Modified) status code and no response body for any Googlebot request: this will save server processing time and resources, which may indirectly improve crawling efficiency.
Another practical action is to hide URLs that we do not wish to be displayed in search results: wasting server resources on superfluous pages can compromise the crawling activity of pages that are important to us, leading to a significant delay in detecting new or updated content on a site. While it is true that blocking or hiding already crawled pages will not transfer crawl budget to another part of the site unless Google is already reaching the site’s publishing limits, we can still work on reducing useful resources, and in particular avoid showing Google a large number of site URLs that we do not want crawled by Search. Typically, these URLs fall into the following categories:
- Facet navigation and session identifiers: facet navigation typically pulls duplicate content from the site, and session identifiers, as well as other URL parameters, sort or filter the page but do not provide new content.
- Duplicate content, generating unnecessary crawling.
- Soft 404 pages.
- Compromised pages, to be searched and corrected through the Security Issues report.
- Endless spaces and proxies.
- Poor quality and spam content.
- Shopping cart pages, continuous scrolling pages, and pages that perform an action (such as pages with invitation to register or purchase).
The robots.txt file is our useful tool when we do not want Google to crawl a resource or page (but reserving revenue only for those pages or resources that we do not want to be displayed on Google for long periods of time); also, if the same resource is reused on multiple pages (such as an image or a shared JavaScript file), the advice is to reference the resource using the same URL on each page, so that Google can store and reuse that resource, without having to request it multiple times.
On the other hand, practices such as assiduously adding or removing pages or directories from the robots.txt file to reallocate the crawl budget for the site and alternating between sitemaps or using other temporary cloaking mechanisms to reallocate the budget are not recommended.
How to reduce Google crawl requests
If the problem is exactly the opposite – and thus we are facing a case of over crawling the site – we have some actions to follow to avoid overloading the site, remembering however that Googlebot has algorithms that prevent it from overloading the site with crawl requests. Diagnosis of this situation should be done by monitoring the server to verify that indeed the site is in trouble due to excessive requests from Googlebot, while management involves:
- Temporarily return 503 or 429 HTTP response status codes for Googlebot requests when your server is overloaded. Googlebot will try again to crawl these URLs for about 2 days, but returning “no availability” type codes for more than a few days will result in slowing down or permanently stopping crawling URLs on the site (and removing them from the index), so we need to proceed with the other steps
- Reduce the Googlebot crawl frequency for the site. This can take up to two days to take effect and requires permission from the user who owns the property in Search Console, and should only be done if in the Host Availability > Host Usage graph of the Crawl Statistics report we notice that Google has been performing an excessive number of repeated crawls for some time.
- If scan frequency decreases, stop returning HTTP response status codes 503 or 429 for scan requests; if you return 503 or 429 for more than 2 days.
- Perform scan and host capacity monitoring over time and, if necessary, increase the scan frequency again or enable the default scan frequency.
- If one of AdsBot’s crawlers is causing the problem, it is possible that we have created dynamic search network ad targets for the site and Google is attempting to scan it. This scan is repeated every two weeks. If the capacity of the server is not sufficient to handle these scans, we may limit the ad targets or request an increase in posting capacity.
Optimizing crawl budget for SEO, best practices
An in-depth article in Search Engine Land by Aleh Barysevich presents a list of tips for optimizing the crawl budget and improving a site’s crawlability, with 8 simple rules to follow for each site:
- Don’t block important pages.
- Stick to HTML when possible, avoiding heavy JavaScript files or other formats.
- Fix redirect chains that are too long.
- Report URL parameters to Googlebot.
- Fix HTTP errors.
- Keep sitemaps up to date.
- Use rel canonical to avoid duplicate content.
- Use hreflang tags to indicate country and language.
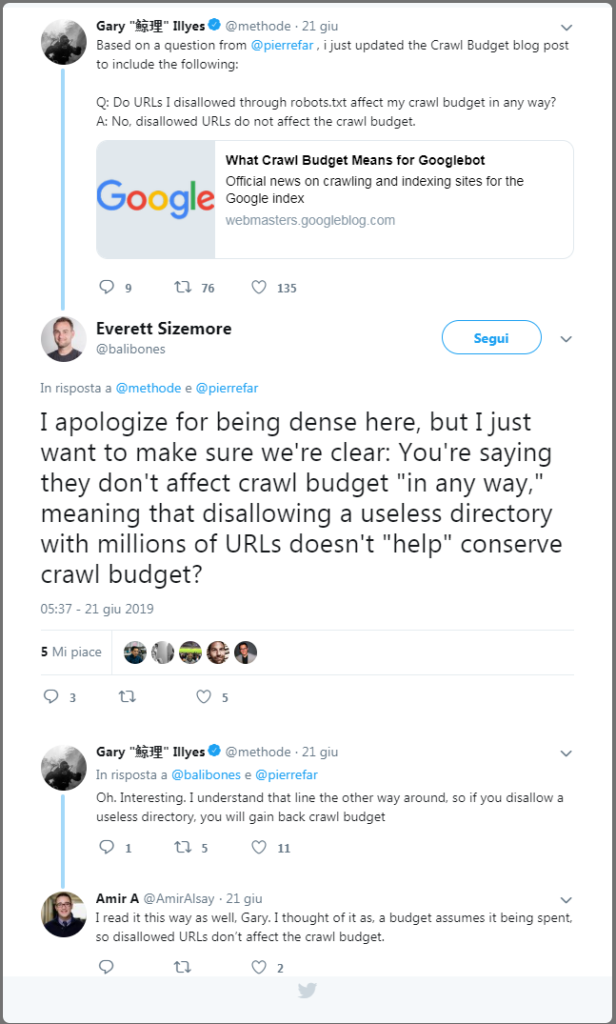
Another technical tip for optimizing a site’s crawl budget comes from Gary Illyes, who explains how setting the disallow on irrelevant URLs allows you to not weigh down the crawl budget, and therefore using the disallow command in the robots file can allow you to better manage Googlebot crawling. Specifically, in a Twitter conversation, the Googler explained that “if you use disallow on a useless directory with millions of URLs you gain crawl budget,” because the bot will spend its time analyzing and crawling more useful resources on the site.
Possible interventions of optimization on the site
In addition to the ones described above, there are also some specific interventions that could help to better manage the crawl budget of the site: nothing particularly “new,” given the fact that these are some well-known signs of the health of the website.
First piece of advice is almost trivial: to allow the scanning of important pages of the site in the robots.txt file, a simple but decisive step in order to have under control the scanned and blocked resources. Likewise, it is good to take care of the XML sitemap, so to give the robots a simple and faster way to understand where the internal connections lead; just remember to only use the canonical URLs for the sitemap and to always update it to the most recent loaded version of the robots.txt.
It would then be good to verify – or avoid altogether – redirect chains, which force Googlebot to scan multiple URLs: in the presence of an excessive share of redirects, the search engine’s crawler could suddenly end the scan without reaching the page it needs to index. If the 301 and 302 should be limited, though, other HTTP status codes are even more harmful: pages in 404 and 410 technically consume crawl budget and, plus, damage the user experience of the site. No less annoying are the 5xx errors related to the server, which is why it is good to do a periodic analysis and a health checkup of the site, maybe using our SEO spider!
Another consideration to be made is about URL parameters, because separate URLs are counted by crawlers as separate pages, and therefore waste an invaluable part of the budget and also risk to raise doubts about duplicate content. In the case of multilingual sites, then, we must make the best use of the hreflang tag, informing in the clearest way possible Google of the geolocated versions of the pages, both with the header and with the <loc> element for a given URL.
A basic choice to improve scanning and simplify Googlebot’s interpretation could be to always prefer HTML to other languages: even if Google is learning to manage JavaScript more effectively (and there are many techniques for the SEO optimization of JavaScript), the old HTML still remains the code that gives us more guarantees.
The critical SEO issues of the crawl budget
One of the Googlers who has most often addressed this issue is John Mueller who, in particular, has also reiterated on Reddit that there is no benchmark for Google’s crawl budget, and therefore there is no optimal benchmark “number” to strive toward with site interventions.
What we can do, in practical terms, is to try to reduce waste on the “useless” pages of our site-that is, those that do not have keyword rankings or that do not generate visits-in order to optimize the attention Google gives to content that is important to us and that can yield more in terms of traffic.
The absence of a benchmark or an ideal value to which tender makes all the discussion about crawl budget is based on abstractions and theories: what we know for sure is that Google is usually slower to crawl all the pages of a small site that does not update often or does not have much traffic than that of a large site with many daily changes and a significant amount of organic traffic.
The problem lies in quantifying the values of “often” and “a lot,” but more importantly in identifying an unambiguous number for both huge, powerful sites and small blogs; for example, again theoretically, an X value of crawl budget achieved by a major website could be problematic, while for a blog with a few hundred pages and a few hundred visitors per day it could be the maximum level achieved, difficult to improve.
Prioritizing pages relevant to us
Therefore, a serious analysis of this “indexing search budget” should focus on overall site management, trying to improve the frequency of results on important pages (those that convert or attract traffic) using different strategies, rather than trying to optimize the overall frequency of the entire site.
Quick tactics to achieve this are redirects to take Googlebots away from less important pages (blocking them from crawling) and the use of internal links to funnel more relevance on the pages you want to promote (which, ça va sans dire, must provide quality content). If we operate well in this direction – also using SEOZoom’s tools to check which URLs are worth focusing on and concentrating resources on – we could increase the frequency of Googlebot passes over the site, because Google should theoretically see more value in sending traffic to the pages it indexes, updates and ranks the site.
Figuring out if Google likes a site without Search Console (and with SEOZoom)
If we do not have access to Search Console (e.g., if the site is not ours), there is still a way to figure out if the search engine is appreciating the site thanks to SEOZoom and Zoom Authority, our native metric that immediately pinpoints how influential and relevant a site is to Google.
The ZA takes into account many criteria and, therefore, not only pages placed in Google’s top 10 or the number of links obtained, and so a high value equals an overall liking by the search engine, which rewards that site’s content with frequent visibility-and we can also analyze relevance by topic through the Topical Zoom Authority metric.
Even more specifically, SEOZoom’s revamped Pages section and the “Page Yield” tool categorizes the web pages of each project-entered site and groups them according to search engine performance, so we know clearly where to take action, how to do it, and when it’s time to eliminate unnecessary or duplicate pages that waste crawl budget.

Basically, this tool gives us a concise and immediate view of the URLs that engage and waste the most crawler resources, so that we can take action and make the overall site management more effective.
Final thoughts on the crawl budget
All in all, it should be pretty clear that having the crawl budget under control is very important, because it can be a positive indication that Google likes our pages, especially if our site is being crawled every day, several times a day.
According to Illyes – the author back in 2017 of an in-depth discussion on Google’s official blog – however, the crawl budget should not be too much of a concern if “new pages tend to be crawled the same day they are published” or “if a site has fewer than a few thousand URLs,” because this generally means that Googlebot crawling is working efficiently.
Other public voices at Google have also often urged site owners and webmasters not to be overly concerned about crawl budgets, or rather not to think exclusively about absolute technical aspects when performing onsite optimization efforts. For example, in a Twitter exchange John Mueller advises rather to focus first on the positive effects in terms of user experience and increased conversions that might result from this strategy.
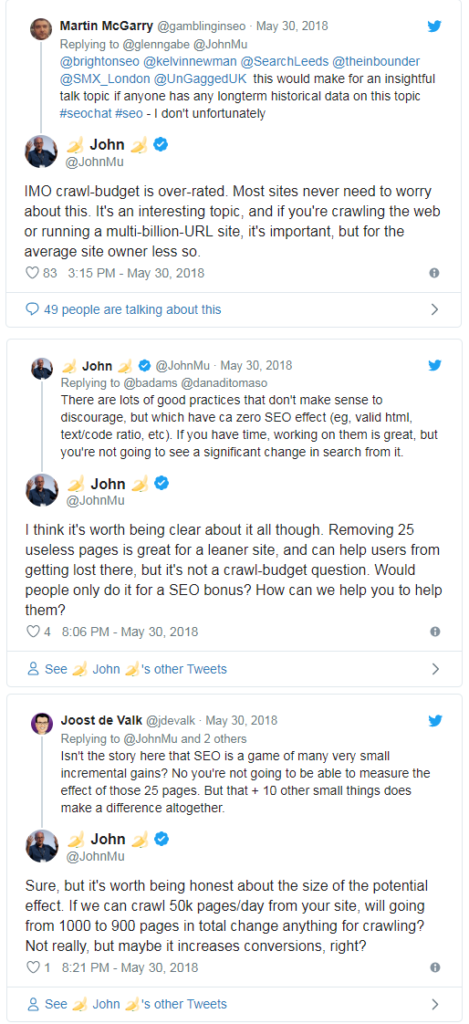
To be precise, Search Advocate argues that there are many best practices for optimizing crawl budget, but they may have little practical effect: for example, removing 25 unnecessary pages is a great way to make sites leaner and prevent users from getting lost while browsing, but it is not something that should be done to improve crawl budget (crawl-budget question) or to hope for concrete ranking feedback.
How does crawl budget and rendering work? Google’s summary
And it is John Mueller himself who gives us some concise, but nonetheless interesting, pointers on crawl budget, techniques to try to optimize its management, and related aspects, such as caching or reduction of embedded resources and their impact on site speed for users.
The starting point for this reflection, which is explored in depth in an episode of the #AskGooglebot series, stems from a user’s question via Twitter, asking if “heavy use of WRS can also reduce a site’s crawl budget.”
As usual, the Search Advocate clarifies the definitions of terms and activities, reminding that:
- WRS is the Web Rendering Service, which is the system that Googlebot uses to render pages like a browser, so it can index everything the same way users would see it.
- Crawl Budget refers to the system that “we use to limit the number of requests we make to a server so that we don’t cause problems during our crawling.”
How Google manages the crawl budget of a site
Mueller reiterates once again that the crawl budget is not a theme that should worry all sites (it was also mentioned in the SEO Mythbusting series), since generally “Google has no problem crawling enough URLs for most sites.” Although there is no specific threshold or benchmark reference, according to the Google Webmaster Trends Analyst the crawl budget “is a topic that should mostly affect large websites, those with over hundred of thousand URLs.”
In general, Google systems can automatically determine the maximum number of requests a server can process over a given period of time. This operation is “done automatically and adjusted over time,” Mueller explains, because “as soon as we see that the server starts to slow down or to return server errors, we reduce the crawl budget available to our crawlers.”
Google and rendering
The Googler also focuses on rendering, explaining to sites that the services of the search engine must “be able to access embedded content, such as Javascript files, CSS, files, images and videos and server responses from the Apis that are used in the pages.”
Google makes a “wide use of caching to try to reduce the number of requests needed to render a page, but in most cases the rendering is more than a simple request, so more than a simple HTML file that is sent to the server.”
Reducing embedded resources helps users as well
Ultimately, according to Mueller, especially when operating on large sites can be of help for crawling “to reduce the number of embedded resources needed to render a page.”
This technique also allows you to offer faster pages to users and to then achieve two key results for our strategy.
Doubts and false myths: Google clarifies questions about crawl budget
The ever-increasing relevance of the topic has led, almost inevitably, to the emergence and proliferation of a great many false myths about the crawl budget, some of which are also listed in Google’s official guide: for example, among the definitely false news are that
- We can control Googlebot with the “crawl-delay” rule (actually, Googlebot does not process the non-standard “crawl-delay” rule in the robots.txt file).
- Alternate URLs and embedded content do not count toward the crawl budget (any URL that Googlebot crawls is counted toward the budget).
- Google prefers clean URLs with no search parameters (it can actually crawl parameters).
- Google prefers old content, which carries more weight, over new content (if the page is useful, it stays that way regardless of the age of the content).
- Google prefers content to be as up-to-date as possible, so it pays to keep making small changes to the page (content should be updated as needed, and it does no good to make revamped pages appear by only making trivial changes and updating the date).
- Crawling is a ranking factor (it is not).
The crawl budget was also the focus of an appointment with SEO Mythbusting season 2, the series in which Google Developer Advocate Martin Splitt tries to dispel myths and clear up frequent doubts about SEO topics.
Specifically, in the episode guesting Alexis Sanders, senior account manager at the marketing agency Merkle, as guest, the focus went to definitions and from crawl budget management tips, a topic that creates quite a few difficulties of understanding for those working in search marketing.
Martin Splitt then began his insight by saying that “when we talk about Google Search, indexing and crawling, we have to make some sort of trade-off: Google wants to crawl the maximum amount of information in the shortest possible time, but without overloading the servers,” i.e., finding the crawl limit or crawl rate.
The definition of crawl rate
To be precise, the crawl rate is defined as the maximum number of parallel requests that Googlebot can do simultaneously without overloading a server, and so basically it indicates the maximum amount of stress that Google can exert on a server without bringing anything to the crash or generating inconvenience for this effort. But Google must pay attention not only to the resources of others, but also to its own, as “the Web is huge and we cannot scan everything all the time, but make some distinctions,” explains Splitt.
For example, he continues, “a news site probably changes quite often, and so we probably have to keep up with it with a high frequency: on the contrary, a site about the history of kimchi will probably not change so assiduously, as history does not have the same rapid pace as the news industry”.
What is the crawl demand
This explains what crawl demand is, that is the frequency with which Googlebot scans a site (or, better, a type of site) based on its probability of updating. As Splitt says in the video, “we try to understand if it is the case to pass more often or if instead we can give a check from time to time”.
The decision process of this factor is based on the identification that Google makes of the site at the first scan, when it basically takes the “fingerprints” of its contents, seeing the topic of the page (which will also be used for deduplication, at a later stage) and also analyzing the date of the last change.
The site has the ability to communicate the dates to Googlebot – for example, through structured data or other time elements on the page – that “more or less keeps track of the frequency and type of changes: if we detect that the frequency of changes is very low, then we will not scan the site with particular frequency”.
The scanning frequency does not concern the quality of contents
Very interesting is the subsequent clarification of the Googler: this scanning rate has nothing to do with quality, he says. “You can have fantastic contents that fit perfectly, that never change”, because the matter in this case is “whether Google must pass frequently on the site for a crawling or it can rather leave it alone for a certain period of time”.
To help Google answer this question correctly, webmasters have at their disposal various tools that give “suggestions”: in addition to the aforementioned structured data, you can use Etag or HTTP headers, useful to report the date of the last change in the sitemap. However, it is important that the updates are useful: “If you only update the date in the sitemap and we realize that there is no real change on the site, or that they are minimal changes, you are not helping” in identifying the likely frequency of changes.
When the crawl budget turns into an issue?
According to Splitt, the crawl budget is still a priority theme that should interest or worry huge sites, “let’s say with millions of urls and pages”, unless you “have a shoddy and unreliable server”. But in that case, “more than crawl budget you should focus on server optimization,” he continues.
Usually, according to the Googler, there is a talk about crawl budget that is out of place, that happens when there is no real problem related; to him, crawl budget issues happen when a site notices that Google discovers but does not scan the pages he cares about for a long time and those pages do not present any problems or errors whatsoever.
In most cases, however, Google decides to scan but not index pages because “it is not worth it because of the poor quality of the contents present”. Typically, these urls are marked as “excluded” in the Index coverage report of the Google Search Console, clarifies the video.
The crawl frequency is not a quality signal
Having a site scanned with high frequency is not necessarily a help to Google because the crawl frequency is not a signal of quality, explains Splitt, as for the search engine is still OK to “have something crawled, indexed and that doesn’t change anymore” and does not require any more bot steps.
Some more targeted advice comes for e-commerces: if there are many small pages very similar to each other with similar contents, you should think about their usefulness wondering if their existence even makes sense. Or, maybe to consider extending the content so to make it better? For instance, if they are only products that vary by a small feature, they could be grouped into a single page with a descriptive text that includes all possible variations (instead of having 10 small pages for each possibility).
The weight of Google on servers
The crawl budget connects to a number of issues, so: among those mentioned there are precisely the duplication or search of pages, but the speed of the server is a sensitive issue, as well. If the site relies on a server that occasionally collapses, Google may have difficulty understanding whether this happens due to the poor characteristics of the server or due to an overload of its requests.
Speaking of managing server resources, then, Splitt also explains how the activity of the bot works (and then what it sees in the log files) suring the early stages of Google’s discovery or when, for example, you perform a server migration: initially, an increase in crawling activity, followed by a slight reduction, which then continues to create a wave. Often, however, the change of servers does not require a new rediscovery by Google (unless you switch from something broken to something that actually works!) and then the crawling activity of the bot remains stable as it was before the switch.
Crawl budget and migration, Google’s suggestions
Rather sensitive is also the management of Googlebot’s scanning activity during the overall migrations of the site: the advice that comes from the video to those who are in the middle of these situations is to progressively update the sitemap and report to Google what is changing, so as to inform the search engine that there were useful changes to follow and verify.
This strategy gives webmasters a little control over how Google discovers changes during a migration, although in principle you can also simply wait for the operation to complete.
What matters is to ensure (and be sure) that both servers are functioning and working regularly, without sudden momentary collapses or status codes of error; it is also important to set the redirects correctly and verify that there are no significant resources blocked on the new site through a robots.txt file not properly updated to the new post migration site.

How the crawl budget works
A question by Alexis Sanders brings us back to the central theme of the appointment and allows Martin Splitt to talk about how the budget crawl works and on what level of the site it intervenes: usually, Google operates on the site level, so considers everything on the same domain. Subdomains can be scanned at times, while in other cases they are excluded, while for CDNs “there is nothing to worry about”.
Another practical suggestion that comes from the Googler is the management of user-generated contents, or more generally the anxieties about the amount of pages on a site: “You can tell us not to index or not to scan contents that is of low quality”, Splitt reminds us, and so for him the crawl budget optimization is “something that concerns more the contents side than the technical infrastructure aspect”, (approach that is perfectly in line with the one of our SEOZoom tools!).
Do not waste Google’s resources and time
Ultimately, working on the crawl budget also means not wasting Google’s time and resources, also through a number of very technical solutions such as cache management.
In particular, Splitt explains that Google “tries to be as aggressive as possible when caching sub-resources, such as CSS, Javascript, API calls, all that sort of thing”. If a site has “API calls that are not GET requests, then we can’t cache them, and so you have to be very careful about making POST requests or something similar, which some APIs do by default”, because Google cannot “cache them and this will consume the site’s crawl budget faster“.