
Googlebot: what is it and what does the Google crawler do
It sits behind the scenes, but it is a major player in the operation of Google Search. Googlebot is the fundamental spider software with which Google manages to scan the pages of public Web sites, following the links that start from one page and connect it to others on the Web and thus selecting the resources that deserve to enter the search engine’s Index. The name immediately makes one think of something nice, and indeed even the corporate image confirms this feeling.Behind this is a sophisticated algorithm that constantly scans the Web for new content, updates or changes to existing pages. In short, this little robot is the basis of the entire Google crawling and indexing process , from which it then derives its ranking system.In this article, we will find out not only what Googlebot is, but also how it works, why it is crucial for SEO, and what are the best practices to facilitate its work.
What is Googlebot
Googlebot is Google’s web crawler , an automated tool that continuously explores web pages to gather useful information and populate Google’s search engine index.

Basically, Googlebot is the invisible brain that allows Google to know and interpret the infinite data on billions of websites, scanning the Web for sites and content automatically and continuously.
Crawlers or spiders are other terms used to describe this type of software, as bots such as Googlebots move from site to site, “scrolling” through hyperlinks in a process akin to the behavior of a spider weaving its web. In this incessant work, Googlebot scans and analyzes pages and then determines their relevance, so that the ranking algorithm can present us with the search results best suited to our queries.
What Googlebot means
The name Googlebot comes from the combination of the word “Google” (the meaning of which does not need much explanation) and “bot,” which is simply an abbreviation for robot. This term perfectly describes the automatic nature of the tool, which operates as a real “little robot” capable of scanning the web in an autonomous and predetermined manner.
The official image of Googlebot depicts precisely a cute little robot with a lively look vaguely similar to Wall-E, ready to launch itself on a quest to find and index knowledge in all the still unknown corners of the Web. For some time now, then, the Mountain View team has also joined him with a spider-bot, a kind of additional sidekick or mascot called Crawley, which serves to emphasize even more the “work” performed by these software.
If we want to provide a definition of Googlebot, we can say that it is basically a program that performs three functions: the first is crawling, the in-depth analysis of the Web in search of pages and content; the second is indexing those resources, and the third is ranking, which, however, is more precisely taken care of by the search engine’s special ranking systems.
Basically, the bot takes content from the Internet, tries to figure out the topic of the content and what “materials” can be offered to users searching for “these things,” and finally determines which of the previously indexed resources is actually the best for that specific query at that particular time.
Behind its pretty appearance, therefore, is a powerful machine that scans the Web and adds pages to its index constantly: it is therefore (also) to its credit that we can go to Google and get results relevant to our searches!
What Googlebot does and what it is used for
We can call it a spider, a crawler or simply a bot, but it does not change the essence of its mechanism. Googlebot is special software that scans the web following links it finds within pages to find and read new or updated content and suggest what should be added to the Index, the ever-expanding inventory library from which Google directly pulls online search results.
This software enables Google to compile more than 1 million GB of information in a fraction of a second. In practice, without this activity Google would have no way to create and update its index with billions of pages from around the world, and to do so with the speed required today.
More precisely, then, Googlebot is the generic name for two different types of crawlers: a desktop crawler that simulates a user using a desktop device, and a mobile crawler that simulates a user using a mobile device.
Sometimes our site is visited by both versions of Googlebot (and in the case we can identify the subtype of Googlebot by examining the user agent string in the request), but with the move to Google’s mobile-first approach , almost all Googlebot crawl requests are made using the mobile crawler.
Also, again from a technical point of view, both Googlebot desktop and Googlebot mobile share the same product token (user agent token) in the robots.txt file, so we cannot selectively set Googlebot for smartphone or Googlebot for desktop as the target using the robots.txt file.
Why it is relevant in SEO
The relevance of Googlebot in SEO is immediately understandable: without a thorough and regular crawl of our web pages, Google is unable to include them in its index, precluding us from being visible in SERPs. To put it another way, a site that is not properly scanned by Googlebot is as if it does not exist.
For SEO practitioners, however, Googlebot represents more than just a tool to depend on: it is the most important “visitor” a site can receive, because its scans determine whether and how our site will be visible on the screens of billions of users. But there’s more: it’s not enough for Googlebot to visit the site, it’s crucial that it can understand it correctly. And this is where our ability to best optimize web pages comes into play .
SEO, then, should be based primarily on the ability to optimize one’s content so that Googlebot can find it, scan it, and index it correctly.
Basically, Googlebot is the direct thread between our site and the vast world of Google searches. By optimizing our pages for the crawler to scan them correctly, we give Google a way to show them to the right users, at the right time, resulting in dramatically improved visits as well as overall visibility of our site.
What are the other Google bots
Googlebot is only Google’s main crawler, but it is not the only one and indeed there are several bots, which have specific tasks and can be included in three broad categories, as the official Mountain View document explains. In fact, Google uses crawlers and fetchers (tools such as a browser that require a single URL when requested by a user) to perform actions for its products, either automatically or triggered at the user’s request.

The list of these tools includes:
- Common crawlers, most notably Googlebot, which are used to create Google search indexes, perform other product-specific scans, and for analysis. As a distinguishing feature, they always abide by the rules in the robots.txt file, have as their inverted DNS mask “crawl-***-***-***-***.googlebot.com or geo-crawl-***-***-***.geo. googlebot.com,” and the list of IP ranges is found in the specific googlebot.json file.

- Special case crawlers : crawlers that perform specific functions, used by specific products where there is an agreement between the crawled site and the product regarding the crawling process, and which may or may not comply with robots.txt rules. For example, AdSense and AdsBot control the quality of ads, while Mobile Apps Android controls Android apps, Googlebot-Image tracks images, Googlebot-Video videos, and Googlebot-News the news. Their reverse DNS mask is “rate-limited-proxy-***-***-***-***.google.com” and the list of IP ranges can be found in the special-crawlers.json file (and is different from those of common crawlers).

- User-activated fetchers: tools and product functions where the end user activates a fetch (fetch), such as Google Site Verifier acting on a user’s request. Because the fetch was requested by a user, these fetchers ignore robots.txt rules. Their reverse DNS mask is “***-***-***-***.gae.googleusercontent.com” and the list of IP ranges can be found in the user-triggered-fetchers.json file. Google-controlled crawlers originate from the IPs in the user-triggered-fetchers-google.json object and resolve to a hostname google.com. The IPs in the user-triggered-fetchers.json object resolve to the host names gae.googleusercontent.com. These IPs can be used, for example, when a site hosted on Google Cloud (GCP) needs to retrieve external RSS feeds at the request of a user.

This official mirror helps us keep an eye on all the possible (mostly desired) visitors to our site and pages, broken down into the three categories just described.
The guide also makes it clear that there are two methods for checking Google crawlers:
- Manually: for single searches, through the command-line tools. This method is sufficient for most use cases.
- Automatically: for large-scale searches, with an automated solution to compare a crawler’s IP address with Googlebot’s list of published IP addresses.
How Googlebot works: the crawling and indexing process
As mentioned, the heart of Googlebot ‘s activity is the crucial process of crawling, the phase in which the bot starts moving through the pages of our site, following internal and external links, looking for new content or updates to add to its database.
Google crawling is an ongoing, methodical activity designed to ensure that the search engine always has an up-to-date view of the web.
However, Googlebot does not crawl every corner of every site in the same way, with the same priority nor with the same frequency-that is the concept behind crawl budget. Some pages may be visited more often, others less often, and some may not be crawled at all (unless precise instructions are given, such as robots.txt files or the noindex attribute ).
Basically, Googlebot begins its process by selecting a list of URLs to visit. This list is constantly updated with new pages, which can be flagged by various factors such as the existence of new links, sitemaps, or direct intervention via the Search Console. Once started, the bot follows a website’s internal links by “crawling” from one page to the next: this behavior is why we often refer to Googlebot as a spider, a designation that emphasizes its spider-like ability to “weave” the web, catching links and content as it goes.
During crawling, Googlebot reads the HTML code of pages and gathers crucial information about them, such as text content, images, CSS and JavaScript files. For example, a newly published or updated page can be scanned for quality, relevance, and even internal and external link structure. These scans help Google determine whether a page is valid for inclusion in its index. Its main goal is to ensure that Google has an up-to-date and relevant inventory of online resources, enabling the search engine to return the most relevant results to users’ queries.
The crawler is used to locate, examine and “snapshot” the content of a site to prepare it for the next step, which is indexing. Therefore, SEO optimizations should not only focus on the content visible to users, but also on those technical aspects that allow Googlebot to find and understand pages in the best possible way. In fact, a site with complex navigation or non-interlinked pages may be difficult to scan, hurting Google’s automatic indexing.
How Googlebot organizes information
Once the crawling process is complete, we move on to the indexing phase , during which all the information collected is sorted, stored and made searchable in Google’s vast database.
This process allows Google to assign a “place” to each crawled page within its online “library,” from which search results are subsequently extracted.
Think of the index as a kind of archive that can be consulted in real time: after a page has been scanned, Googlebot decides what to do with the information collected. Not all pages, in fact, are immediately indexed or shown in the SERPs, because Google uses a number of factors to determine whether a page deserves to be permanently archived and displayed among the results-the very famous 200 ranking factors.
We are inclined to view crawling and indexing as two separate activities, but they are actually closely related: successfulindexing depends on the quality and accuracy of the initial crawling . If Googlebot fails to crawl a site properly, for example due to technical errors or blocked pages, the natural consequence will be incomplete or faulty indexing, which hinders our potential ranking.
Finally, indexing allows Google to create a snapshot of a web page, such as a digital copy that can later be accessed and presented in the results in milliseconds, when a user enters relevant queries .
Google ranking and Googlebot: what is the relationship?
It is appropriate at this point to better clarify the concept of Googlebots and ranking, referring also to an (old) video from SEO Mythbusting, the series on YouTube made by Martin Splitt who, prompted by the requests of many webmasters and developers and the precise question of Suz Hinton (at the time Cloud Developer Advocate at Microsoft), went to great lengths to clarify some features of this software.
In particular, the developer advocate from the Google Search Relations team specified that the Google ranking activity is informed by Googlebot, but is not part of Googlebot.
This therefore means that during the indexing phase, the program ensures that the crawled content is useful for the search engine and its ranking algorithm, which uses, as we mentioned, its specific criteria to rank pages.
An example to understand the relationship: the Search as a library
Thus, the aforementioned similarity with a library, in which the manager “must determine what the content of the various books is in order to give the right answers to the people who borrow them, comes in handy. To do this, he consults the catalog of all the volumes present and reads the index of the individual books.”
The catalog is thus the Google Index created through Googlebot scans, and then “someone else” uses this information to make thoughtful decisions and present users with the content they request (the book they want to read, to continue the analogy provided).
When a person asks the librarian “what is the best book to learn how to make apple pies very quickly,” the librarian should be able to answer appropriately by studying the subject indexes of the various books that talk about cooking, but also know which ones are the most popular. Thus, in the Web sphere we have the index provided by Googlebot and the “second part,” ranking, which is based on a sophisticated system that studies the interaction between the content present to decide which “books” to recommend to the enquirer.
A simple, non-technical explanation of scanning
Splitt later returned to clarify the analogy about how Googlebot works , and a SearchEngineLand article quotes his words to explain in a non-technical way the scanning process of Google’s crawler.
“You’re writing a new book and the librarian has to actually take the book, figure out what it’s about and also what it relates to, whether there are other books that might have been source or might be referenced by this book,” the Googler said. In his example, the librarian is Google’s web crawler, or Googlebot, while the book is a website or Web page.
Simplifying, the process of indexing then works like this, “You have to read [the book], you have to understand what it’s about, you have to understand how it connects to other books, and then you can sort it in the catalog.” Therefore, the content of the web page is stored in the “catalog, ” which out of metaphor represents the index of the search engine, from where it can be ranked and published as a result for relevant queries.
In technical terms, this means that Google has “a list of URLs and we take each of those URLs, make a network request to them, then look at the server’s response and then render it (basically, open it in a browser to run JavaScript); then look at the content again and then put it in the index where it belongs, similar to what the librarian does.”
The history and evolution of Googlebot
When we think of Googlebot today, we imagine it as a sophisticated crawler capable of handling massive amounts of data distributed across billions of web pages. But this was not always the case. Googlebot ‘s history is one of constant evolution, fueled by the growing need to deliver increasingly relevant and accurate search results to users. Early versions of this Google spider were significantly less complex than today’s, but each transformation marked fundamental advances in crawling optimization and, consequently, SEO strategies.
Initially, Google focused on a bot that could gather basic information from web pages and make it available for indexing. While already an advanced technology compared to many other bots of the 1990s, Googlebot was limited to scanning text, ignoring more complex elements that we see as central today, e.g., JavaScript or CSS files. Over time, however, its role gradually expanded. As the Web evolved, becoming more dynamic and interactive, Googlebot also had to adapt. SEO was beginning to take hold, and companies and webmasters were constantly looking for new ways to optimize their websites.
One of the major changes that characterized this bot was the ability to handle dynamic content created through JavaScript, a challenge that required significant improvement in terms of computational resources and processing power. With the introduction of the so-called enhanced Googlebot Crawl , Google began to make it possible to read and interpret much more complex and interactive websites, directly contributing to improving the SEO capabilities of all those who leveraged Static Sites Generators or advanced frameworks.
Over time, Google also gave webmasters more advanced tools to closely monitor Googlebot interactions on their sites. Every Googlebot access to the site is potentially visible via the server log, where it is possible to identify Googlebot IPs and control what parts of the site are being scanned, how often, and what kind of response the server sends. This has had a profound impact on technical SEO monitoring , allowing critical errors to be corrected and preventing crawlers from getting lost in less relevant sections of the site.
Another significant evolution comes with the transition of indexing to mobile-first, which marked a turning point for Googlebot. With the exponential increase in users browsing from mobile devices, Google introduced specific variations of the bot, such as Googlebot mobile, designed to scan the mobile version of a site and assess its usability, readability, and speed. In this way, Google discovers content using a mobile user agent and a mobile viewport, which serves the search engine to make sure it is serving something visible, useful, and pretty to people browsing from a mobile device.
This shift has profoundly changed the way developers and SEO specialists design and implement their optimization strategies, as it is now crucial to ensure that sites are perfectly optimized for mobile devices as Googlebot mobile takes precedence in crawling. In this sense, the concept of mobile readiness or mobile friendliness becomes central : making a page mobile friendly means making sure that all content falls within the viewport area, that the “tap targets” are wide enough to avoid pressure errors, that the content can be read without necessarily widening the screen, and so on, as Splitt already explained, also because these elements are an indicator of quality for Google. Although in the end the advice the analyst gives is to “offer good content for the user” because that is the most important thing for a site.
The evergreen Googlebot, to respond to technological evolutions
As of May 2019 for Big G’s crawler there was a fundamental technical change: to ensure support for the newest features of web platforms, in fact, Googlebot became evergreen and continuously updated, equipped with an engine capable of constantly managing the latest version of Chromium when rendering web pages for Search.
According to Google, this feature was the “number one request” from participants at events and social media communities with respect to implementations to be made to the bot, and so the California team focused on making GoogleBot always up-to-date with the latest version of Chromium, carrying out years of work to work on Chromium’s deep architecture, optimize layers, integrate and run rendering for Search, and so on.
In concrete terms, since that time Googlebot has become capable of supporting more than a thousand new features, such as in particular ES6 and new JavaScript features, IntersectionObserver for lazy-loading, and Web Components API v1. Until May 2019, GoogleBot had been deliberately kept obsolete (to be precise, the engine was tested on Chrome v41, released in 2015) to ensure that it would index Web pages compatible with earlier versions of Chrome. However, increasing disruptions for websites built on frameworks with features not supported by Chrome 41-which then suffered the opposite effect and encountered difficulties-made the change necessary.
The decision to make GoogleBot and its search engine evergreen solves this problem and, at the same time, is positive news for end users, who can now enjoy faster and more optimized experiences.
As written on what was still called Twitter at the time by Ilya Grigorik, Google’s Web performance engineer, there will be no more “transpiling of ES6” or “hundreds of web features that no longer require polyfilling or other alternative solutions” complex, benefiting even the many sites that sent the same transpiled code to everyone.
But the story of Googlebot’s evolution is far from over. Today, with the emergence of technologies such as artificial intelligence, Googlebot has become even “smarter.” With the introduction of AI components in crawling and indexing, Googlebot’s ability to understand natural languages and respond to user queries in a contextual and semantic way is continuously expanding, bringing the search engine closer to a “spider” that no longer just mechanically scans pages, but is able to interpret and understand the intentions behind every signal on the web.
Googlebot and site crawling: managing and optimizing the crawl budget
We’ve said it-and Martin Splitt also reminded us in the aforementioned video: Googlebot does not simply crawl all the pages of a site at the same time, both because of internal resource limitations and to avoid overloading the site service.
So, it tries to figure out how far it can go in crawling, how many of its own resources it has at its disposal, and how much it can stress the site, determining what we have learned to call a crawl budget and which is often difficult to determine.
The crawl budget represents the amount of resources Googlebot devotes to crawling a website. In other words, it is a kind of “time and resource budget” that Google allocates to each site to decide how many pages to crawl and how often. Optimal management of this budget is essential to prevent Googlebot from unnecessarily spending time on less important pages, penalizing the indexing of more important ones.
The crawl budget depends on several factors: the size of the site, the number of changes that are frequently made to pages, the performance of the server, and the overall authority of the site itself. Large sites, such as those with thousands of editorial or e-commerce product pages, need to pay special attention to googlebot crawl optimization, as it is very easy for low-value or duplicate pages to consume resources unnecessarily, negatively affecting the effectiveness of crawling by Googlebot.
“What we do,” Splitt explained, ”is launch a crawl for a while, turn up the intensity level and when we start seeing errors reduce the load.
When does Googlebot scan a site? And how often does Googlebot scan?
Specifically, Splitt also described how and when a site is crawled by Googlebot, “In the first crawling phase we get to your page because we found a link on another site or because you submitted a sitemap or because you were somehow entered into our system. One such example is using the Search Console to report the site to Google, a method that gives the bot a hint and a trigger and spurs it on (hint and trigger).
Connected to this issue is another important point, the frequency of crawling: the bot tries to figure out if among the resources already in the Index there is something that needs to be checked more often. That is, does the site offer news stories that change every day, is it an eCommerce site that offers deals that change every 15 days, or even does it have content that doesn’t change because it is a museum site that rarely updates (perhaps for temporary exhibitions)?
What Googlebot does is separate the index data into a section called “daily or fresh” which is initially crawled assiduously and then reduced in frequency over time. If Google notices that the site is “super spammy or super broken”, Googlebot may not scan the site, just as the rules imposed on the site keep the bot away.
Is my site being visited by Googlebot?
This is the crawler part of Google’s spider, which is followed by other more specific technical activities such as rendering; for sites, however, it can be important to know how to tell if a site is being visited by Googlebot, and Martin Splitt explains how to do this.
Google uses a two-stage browser (crawling and true rendering), and at both times it presents sites with a request with a user agent header, which leaves clearly visible traces in the referrer logs. As noted in official Mountain View documents, Google uses a dozen user-agent tokens, which are responsible for a specific part of crawling (e.g., AdsBot-Google-Mobile checks ad quality on the Android web page).
Sites can choose to offer crawlers not a full version of the pages, but a pre-rendered HTML specifically to facilitate crawling: this is what is called dynamic rendering, which basically means having client-side displayed content and pre-rendered content for specific user-agents, as noted in Google’s guides. Dynamic rendering or dynamic rendering is especially recommended for sites that have JavaScript-generated content, which remains difficult for many crawlers to process, and gives user-agents content that suits their capabilities, such as a static HTML version of the page.
How to facilitate crawling by Googlebot
Optimizing website crawling is one of the most important goals to improve Googlebot’s efficiency and ensure proper indexing. To do this, it is necessary to take steps to make the structure of our site clear and easily navigable. From the proper organization of internal links to the use of robots.txt files and sitemaps, every technical detail matters when it comes to sites with a high amount of content.
The first thing that needs to be done is to make sure that Googlebot can move smoothly within the site. Navigation should be smooth, with well-connected URLs-for example, orphan pages that are not linked by any other URL on the site tend not to be crawled. Another thing to keep an eye on is the issue of server errors: a site with frequent errors or pages that return the infamous 404 not found risks damaging Googlebot’s perception of our overall quality.
Careful management of the robots.txt file is essential to facilitate crawling by the bot, because this file allows us to specify to Googlebot which sections we want to exclude from crawling. Blocking access to irrelevant sections such as internal search pages, backend tools, or the login itself is useful to avoid wasting resources. By doing so, we ensure that Googlebot focuses on the key content to be indexed. At the same time, thanks to XML sitemaps we can provide clear indications of which pages are new, relevant, and up-to-date, helping the bot determine what to scan most frequently.
Another crucial technical aspect is page loading speed. Slow sites risk limiting the number of pages scanned by Googlebot, because the crawler stops scanning on sites that load too slowly. Optimizing images, reducing the weight of CSS and Javascript files is a great starting point for improving overall performance. The goal is to create a site that is fast, responsive and accessible on any device.
Finally, with the increase in searches from mobile devices, it is crucial to pay attention to mobile-first indexing. Googlebot pays special attention to the mobile version of sites, often indexing that as the primary version. Ensuring that our site is optimized for mobile, with a responsive design and fast load times, is now essential to facilitate crawling by Googlebot.
Googlebot and SEO: practical and strategic analysis
We’ve said it before: SEO practitioners cannot overlook the way Googlebot interacts with their site.
The crawler represents the “bridge” between published content and its indexing within the search engine, and it is precisely this relationship that affects organic ranking. The behavior of Googlebot, in fact, affects SEO performance because it affects the frequency of crawling, the indexing of pages and, ultimately, their visibility in the results pages.
Optimizing our SEO strategy ultimately also means knowing how to read the crawl signals left by Googlebot and acting promptly to improve the crawler’s indexing and handling of pages.
One aspect that often goes unnoticed concerns theGooglebot user agent, the specific string that represents the identity that the bot adopts whenever it crawls a website. Googlebot’s user agent varies depending on the type of device it simulates, and there are different user agents for the desktop and mobile versions of the crawler. Monitoring the user agent through server log files allows us to better understand Googlebot’s behaviors and which crawling fires are applied to different sections of the site. With these logs, we can verify that the bot is actually crawling key pages and not visiting secondary priority (or blocked) resources.
Googlebot mobile vs desktop: differences and technical considerations
With the adoption of mobile-first indexing, completed in 2024, Googlebot ‘s focus has shifted from desktop to mobile devices. This is not just a technical issue, but reflects how Google continually adapts its approach to the new habits of users, who increasingly search and browse on mobile devices. This is why distinguishing between the mobile and desktop versions of Googlebot has become crucial to optimizing our website.
Googlebot mobile is actively engaged in ensuring that mobile versions of sites are of equal standing to desktop versions. This means that the smartphone Googlebot will check not only the correctness of the HTML code, but also the loading speed, the responsiveness of the layout, and the accessibility of the site on smartphones and tablets. The once dominant desktop version of Googlebot now takes a secondary role when it comes to evaluating SEO performance. However, it may still be critical for sites that primarily aim to be enjoyed in desktop formats, such as those with complex content aimed at business users or more elaborate enterprise solutions.
Mobile-first indexing has changed the rules of the game, mandating that content optimized for mobile devices is the primary version to be crawled and indexed. If a page is not optimized for mobile, Googlebot mobile may underestimate its relevance, directly impacting visibility in SERPs. One of the key differences between these two bots is precisely the focus on mobile-optimized elements, such as the ease with which a user can navigate and interact with the page.
With the Google Search Console reports and especially the Core Web Vitals benchmark metrics, we can identify and correct any critical issues related to both versions of the site, checking, for example, whether Googlebot can properly scan the resources on a page and detect any technical obstacles, such as blocked JavaScript or CSS files.
How to track Googlebot passage on the site: tools and techniques
Tracking Googlebot passage on a site is a key aspect of optimizing our SEO strategy and ensuring that the most relevant pages are properly crawled and indexed.
The first reference is the aforementioned Google Search Console, where we find some very useful tools to track and manage crawling activity.
One of the most important is the Crawl Stats Report , the Crawl Statistics Report that provides a detailed overview of how many crawl requests have been made by Googlebot in the past weeks (or months), and includes valuable data such as server response time and any errors encountered during crawling. Although this is aggregate and non-specific data, it is an essential tool for understanding Googlebot’s behavior and checking if there are inefficiencies in page load time or display issues that could negatively impact crawling.

In addition, the URL Check feature allows you to see if an individual page has been scanned and indexed correctly, so you can immediately check for access problems resulting from restrictions in robots.txt files or server errors.
To get a more detailed analysis of Googlebot‘s passage , however, the most comprehensive method is to analyze the server log files , which collect data about each visit to the site, including details such as Googlebot’s IPs, the type of requests made, and the server’s response. In this way, we can have a granular view of which specific IPs linked to Googlebot scanned and the outcome of the requests sent; filtering these logs for Googlebot user-agents allows us to check the bot’s activity in real time and ensure that strategic pages are scanned as expected.
How to block Googlebot? When and why to do it
While essential for the visibility of our site, there are situations when blocking Google crawling on certain sections is a wise and necessary choice. Knowing how to block Googlebot effectively, using the appropriate tools, can help avoid crawling and indexing unwanted or potentially unnecessary pages for our SEO strategy.
The most common method of blocking Googlebot is to use the robots.txt file . This configuration file is used to give directives to crawlers, and can be placed in the root of the site: through special rules, it allows you to restrict the bot’s access to certain pages or folders. For example, it might be useful to block it from crawling pages containing sensitive information, such as admin dashboards or login pages that we do not wish to be indexed in search results. Similar attention can be given to duplicate pages or pages that simply do not offer value for the best indexing of the site.
Another common case where we may want to block Googlebot is to avoid crawling on pages with low SEO content, such as thank you pages after a conversion, internal results pages, or filters in our online shop. In addition to being irrelevant to ranking, these pages can also negatively affect the crawl budget , consuming resources that Googlebot could allocate to more competitive and strategic pages.
Another effective tool to control the crawling of specific pages is the use of the noindex attribute : when included within the HTML code of a page, it does not prevent crawling by Googlebot, but prevents the URL from being indexed in the search engine. In some cases, in fact, blocking it completely using robots.txt may not be the best choice, because preventing it from being crawled also means preventing Googlebot from checking for updates or news on the page. With the noindex tag, on the other hand, the bot continues crawling the content but avoids including it in SERP results, an ideal solution for pages that must remain accessible but not visible to the public.
Care should be taken when deciding to block Googlebots or use noindex: if applied without a clear strategy, they could have unintended consequences on the overall indexing of the site. Each excluded page could affect the overall visibility of the site, and incorrect configuration could limit or even zero organic traffic. By carefully monitoring log files and performance on Google Search Console before implementing permanent blocks, we can ensure that the block really serves to optimize the crawling path and not limit it.
Where can spider (also called crawler) software be found?
One of the most common questions among those entering the world of SEO and web optimization concerns the availability of a tool that can simulate the behavior of Googlebot or other spiders. In fact, knowing where spider software is located to analyze websites autonomously, just as Googlebot does, is useful in anticipating possible problems with crawling, indexing, or site performance.
Today, there are a number of affordable and scalable spider software that can perform functions very similar to those of Googlebot. One tool widely used by SEO specialists is Screaming Frog SEO Spider. This software, which can be downloaded and run on various operating systems, can scan many pages of a website to generate very detailed reports on any technical errors, broken links, URL redundancies and absent metadata. Screaming Frog offers a crawl simulation similar to that of Googlebot, allowing us to easily detect any gaps in our site and correct them before the Google bot even visits it.
Alternatively, we can also mention Sitebulb and DeepCrawl, not forgetting of course our SEO Spider, which scans a site by following links between pages just like Googlebot does. The SEOZoom spider is a comprehensive and powerful tool for performing a thorough audit of pages, highlighting errors, broken links, blocked files or aspects that prevent proper indexing of resources.
By expanding the use of these SEO tools, it can become much easier to detect and fix technical problems that might otherwise go unnoticed until a compromised Googlebot crawl , ensuring that our site is always in optimal condition for crawling and indexing by Google.
How to handle Googlebot: the official guide with guidance and best practices
Given the delicacy of these aspects and to avoid errors that could compromise proper indexing or crawling of pages, it is more appropriate than ever to refer to the directions in Google’s official guide to perfecting communication between our site and Googlebot. Here we therefore take up key tips directly from Google’s technical documents, aimed at improving crawler management and ensuring that the practices adopted conform to the suggested standards.
Googlebot is divided into two types: the most widely used is Googlebot Smartphone, which simulates a mobile user, followed by Googlebot Desktop, which simulates browsing from a desktop computer. Both crawlers follow the same directives from the robots.txt file , so it is not possible to distinguish between mobile and desktop in handling these directives, although we can still identify the type of access by examining the user-agent in HTTP requests.
Access frequency and bandwidth management.
Googlebot is designed to access the site efficiently, primarily from IPs located in the United States. Each scan aims to minimize the impact on server performance, and thousands of machines distributed around the world are used simultaneously to do this, so as to improve performance and keep up with the pace of Web growth. In addition, to reduce bandwidth usage Google runs many crawlers on computers near the sites they might scan.
Basically, the guide indicates that Googlebot should not access most sites on average more than once every few seconds; however, for possible delays, this frequency may be slightly higher in short periods.
However, there are situations where the bot’s access frequency could become problematic and overload the server. In these cases, Google offers the possibility of modifying the crawl frequency, reducing it through the advanced settings of the robots.txt file or using the Google Search Console.
Essentially, the system is designed to distribute Googlebot visits and prevent server overload, but it is possible to intervene if slowdowns occur. It is also useful to know that Googlebot can also crawl through HTTP/2, which can reduce the consumption of computing resources (e.g., CPU, RAM) for the site and Googlebot, but without thinking about impacting the indexing or ranking of the site. In case scanning via HTTP/2 is not desired for your site, you can still turn it off via a simple server setting.
Managing Googlebot’s crawl limits.
One of the most relevant technical aspects is the size limit that Googlebot applies to each HTML file or resource scanned. Googlebot scans only the first 15 MB of an HTML or text file, which means that content located beyond this threshold may not be indexed. This limit affects not only HTML but also additional resources such as images, CSS or JavaScript, which are retrieved separately, also subject to the same limit constraint.
The advice here is to ensure that the most important elements-including SEO-relevant text and links-are submitted within the first 15 MB of the content to ensure that they are fully crawled and indexed.
This limit, however, does not apply to resources such as images or videos, because in this case Googlebot retrieves videos and images referenced in the HTML with a URL (e.g.,  ) separately with consecutive retrievals.
) separately with consecutive retrievals.
Google and 15 MB: what the limit means
It was precisely this reference to 15 MB, which first officially appeared at the end of June 2022, that triggered a reaction from the international SEO community, forcing Gary Illyes to write an additional blog entry to clarify the issue.
First, the threshold of the first 15 megabytes (MB) that Googlebot “sees” when retrieving certain file types is not new, but “has been around for many years” and was added to the documentation “because it might be useful for some people when debugging and because it rarely changes.”
This limit applies only to bytes (content) received for the initial request made by Googlebot, not to referenced resources within the page. This means, for example, that if we open https://example.com/puppies.html, our browser will initially download bytes of the HTML file and, based on those bytes, may make additional requests for external JavaScript, images or anything else referenced by a URL in the HTML; Googlebot does the same thing.
For most sites, the 15 MB limit means “most likely nothing” because there are very few pages on the Internet larger than that and “you, dear reader, are unlikely to own them, since the average size of an HTML file is about 500 times smaller: 30 kilobytes (kB).” However, says Gary, “if you are the owner of an HTML page that exceeds 15 MB, perhaps you could at least move some inline scripts and CSS dust to external files, please.”
Data URIs also contribute to the size of the HTML file “because they are in the HTML file.”
To look up the size of a page and thus figure out if we exceed the limit there are several ways, but “the easiest is probably to use the browser and its developer tools.”
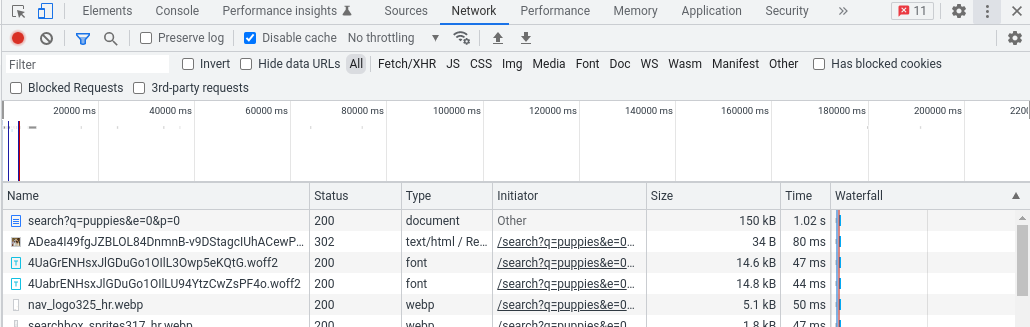
Specifically, Illyes advises, we need to load the page as we normally would, then start the Developer Tools and go to the Network tab; reloading the page we should see all the requests the browser had to make to render the page. The main request is the one we are looking for, with the size in bytes of the page in the Size column.
In this example from Chrome’s Developer Tools the page weighs 150 kB, a figure shown in the size column:
A possible alternative for the more adventurous is to use cURL from a command line, as shown below:
curl
-A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
-so /dev/null https://example.com/puppies.html -w '%{size_download}'Blocking Googlebot access: options and directions for preventing Googlebot from visiting your site
There are several reasons why you might want to prevent Googlebot from accessing certain content, but it is crucial to understand the differences between crawling and indexing, as reiterated in Google’s official guide. If we want to prevent Googlebot from crawling a page, we can use the robots.txt file to block its access. However, if the intent is to prevent a page from appearing in search results, the noindex tag should be used, since blocking only crawling does not guarantee that the page will stay out of SERPs.
Other options for hiding a site from Google include password protection to make certain sections of the site completely inaccessible to both users and bots.
Basically, in fact, it is almost impossible to keep a site secret by not posting links back to it. For example, the guide explains, as soon as a user follows a link from this “secret” server to another web server, the “secret” URL could be displayed in the referrer tag and be stored and published by the other web server in its referrer log.
Before blocking Googlebot, however, it is important to verify the identity of the crawler. In fact, the guide warns us that Googlebot’s HTTP user-agent request header may be subject to spoofing (forgery) by malicious crawlers trying to impersonate Google. Therefore, it is advisable to make sure that the problematic request actually comes from Googlebot: the best way to do this is to use a reverse DNS lookup in the source IP of the request or to match the source IP with Googlebot’s publicly available IP address ranges.