
Google Cache: what it is, how it works, alternatives after dismantling

Goodbye to the Google cache. It’s strange to speak of it in the past tense, but after months of rumors now the official news is here: Google Search no longer shows links to web pages it has stored and has removed the caching functionality completely, while introducing closer collaboration with Internet Archive and its Wayback Machine. It’s a change that marks the end of a feature that for years has been an integral part of users’ search experience and has also often been useful for debugging SEO problems and checking pages. But never fear: there are still alternative ways to view cached copies of web pages, and SEOZoom is involved!
What is the Google cache
The Google cache is a tool that offers users the ability to view an archived version of a web page. This copy of the page is saved the moment Google’s crawler visits the site to index it.




These backups, or snapshots, are available through a specific link placed next to the search result URL in classic SERP preview snippets, traditionally available under a small triangle or in a drop-down menu. Clicking on this link opens the stored version of the page in the browser, as it was at the time of the last crawl.
As Google’s crawlers explore and index the web, it regularly creates and updates these archives, thus providing a valuable resource for accessing content that may no longer be available on the original site.
In essence, it is a kind of digital time machine to allow users to access earlier versions of a web page. Indeed, it was: as mentioned, the feature was retired during 2024 because Google chose to approach the archiving of historical versions of web pages differently, aligning (in intentions) its service with expectations of an increasingly stable and agile web.
How Google caching works
We choose to talk about the topic still in the present tense to maintain the “historical memory” of this feature.
How the Google cache works is the result of a complex technical process orchestrated by Googlebot, Google’s crawler designed to explore and catalog the web.
Each time Googlebot visits a web page during the crawling process, it analyzes its content and structure, while also creating a visual copy, or Snapshot, of that page exactly as it is at that moment.
This snapshot is then stored in Google’s servers and becomes accessible as a cached copy, available upon clicking within the SERP, next to the search result.
It is important to understand that the crawler performs this operation autonomously, following its own crawling plan based on how often Google deems it appropriate to visit a page. The frequency with which a page is updated by the crawler, and thus a new version of the cache is created, depends on several factors, including the importance of the site, the frequency of updates, and the structure of the domain.
In the case of dynamic pages, Google may choose to update the cache more frequently, while for static content it may take longer between visits. Not all pages end up in the Google cache: some may be specifically excluded via the robots.txt file, which gives precise directions to crawlers as to where they can or cannot access, or via the noarchive metatag, which explicitly tells Google not to save copies of that page.
The technical process of Google cache storage
The Google cache was thus the result of a complex technical process involving Googlebot and Google’s other crawlers, the automated programs that explore the Web to discover and analyze pages to add toGoogle’s index, which as we know is the database that algorithms draw on to provide search results.
When a Google crawler visited a web page, it not only analyzed its content and structure to understand what the page was about, but also created a copy of it, which was then stored in Google’s servers, becoming a kind of “snapshot” of the page at the time it was visited by the crawler.
This snapshot is what was called Google’s “cache.”
The cache was available primarily for pages that had been indexed by Google, which means as mentioned above that not all web pages ended up in the cache: only those pages that the crawlers had visited and deemed worthy of inclusion in Google’s index could have a version stored in the cache. In addition, some pages could be excluded from the cache for various reasons, such as.
- Robots.txt directives. The file provides instructions to crawlers on which pages should or should not be indexed or cached.
- Metatag Noarchive. A specific robots meta tag in web pages that tells crawlers not to cache that page.
- Technical problems. Sometimes, technical problems or errors may prevent crawlers from properly accessing or caching a page.
- Dynamic content. Pages with highly dynamic or frequently changing content may not always be properly captured in the cache.
- Legal issues. In some cases, Google may remove the cached version of a page as a result of legal issues or removal requests.
What the Google cache is used for.
The Google cache has several practical uses, which made it a valuable tool for both ordinary users and SEO professionals.
For ordinary Web surfers, the cache allowed access to archived pages at times when those pages were temporarily unavailable. When a site was offline due to a technical problem or the page had been removed or modified, the cache link allowed a saved copy to be viewed, thus providing a sort of window into the status of the site in a past version. It was particularly useful in contexts of server overload or momentary service interruptions, when content was temporarily unreachable.
For SEO professionals, caching took on a more strategic role. One of its main functionalities was to allow a version check of a page stored by Google, helping to monitor the current state ofindexing. In this case, it was an essential tool for specific tasks such as SEO debugging with caching, which involved checking the changes made to a page against the version recorded by Google and being able to identify any inconsistencies between the intended content and the content stored by the search engine. In certain situations, caching was also useful for checking whether changes to a page had actually been recorded by Google and how far the crawling and indexing process had progressed.
This ability to provide a time window on web pages thus made it valuable on two levels: first, to allow temporary backup access to content, and second, to provide a more in-depth technical analysis regarding how Google had processed each website. Although today the removal of the cache link in SERPs has changed the way certain operations are performed, the usefulness of Google’s cache remains a staple of SEO and optimization history, remembered especially by those who exploited its potential for technical and professional purposes.
The strategic use of Google’s cache copy
When it was up and running, the Google cache was thus an extremely useful tool because it allowed the content of a page to be seen even if the original site was no longer available or if the page itself had been modified or removed from the web. This was invaluable both to users looking for information and to SEO professionals who wanted to analyze pages from the point of view of indexing and ranking in the results.
It was not just a simple repository of web pages, but a real strategic resource for both ordinary users and web professionals. For users, the cache was a tool for immediate access to content that, for various reasons, might not be temporarily available online, such as during down periods for maintenance or due to traffic overload.
For website owners, then, the cache acts as a lifesaver in downtime situations , allowing visitors to still access content and helping to maintain some continuity in the user experience, at least partially reducing the negative impact of any service interruptions.
In addition, Google’s cache has also been a useful diagnostic tool from an SEO and digital analytics perspective, allowing one to see the latest version of a page that Google has indexed and to understand what elements have been taken into account by the search engine, but also to make sure that the changes made had been recognized and indexed correctly.
The evolution of the cache and why it was abandoned
Theevolution of Google’s cache has closely followed the development of the Web and network technologies.
The feature was introduced back in the early years after its 1998 debut and was one of many innovations that made the difference between Search and other search engines, highlighting Google’s focus on user experience and the quality of its search services. To be sure, Google’s cache quickly became a valued tool for users and Web professionals alike because of its ability to provide access to information that might otherwise have been temporarily or permanently inaccessible.
However, the context of the Web has changed rapidly over the years. For example, in the early 2000s, the Internet infrastructure was still relatively unstable: websites often became inaccessible due to technical problems or server overloads, making the caching function extremely valuable in allowing users to still access earlier versions of pages, even when the original sites were offline.
In the intervening years, however, connection stability and server reliability have improved dramatically. Today, professional websites manage to ensure constant availability of content, with minimal downtime. As the network has become significantly more robust, the importance of having a stored copy of web pages has gradually declined. In parallel, more complex and reliable SEO tools have been introduced, such as those offered by Google Search Console, which can provide detailed information on indexing data without needing access to stored copies.
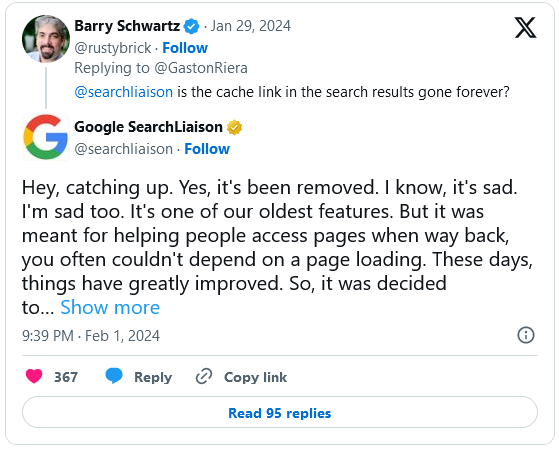
The decision to abandon caching therefore came after a thorough evaluation. Danny Sullivan, Search Liaison at Google, explained that the need for the cache had decreased due to the increased reliability of the global network. At the same time, maintaining the feature entailed non-negligible technical costs for Google, which preferred to redirect its resources to other needs. Google’s cache has thus been set aside in favor of new tools, but it has not completely disappeared, given the decision to provide for Internet Archive integration via the Wayback Machine tool .
Google removes links to cached versions of pages
As mentioned, a significant change takes shape in early 2024 , as Google officially announces the removal of cached links from search results, both on desktop and mobile devices. After weeks of rumors and reports from users and SEO professionals, the decision becomes final in the following weeks, although the actual removal is more gradual.
In practical terms, theelimination of the cache link does not mean that Google has immediately ceased creating page copies for technical purposes: the caching process is closely linked to the internal workings of crawlers, but the function of public access to cache copies through the SERP has been permanently discontinued. To keen observers, the removal did not come as a surprise: as early as December 2023 , some signs had shown that Google was experimenting with caching link removal in limited tests.
Delving into the rationale behind this move, from Google’s perspective the need to display an archived copy of a page was becoming less and less relevant in a web that has evolved toward greater reliability, stability, and transparency. Storing pages in servers for public access became, in the modern context, an onerous process, draining technological and data processing resources. Add to this Google’s strategic intention to incentivize the use of more specific, high-performance tools, as Google Search Console and other advanced diagnostic platforms available to webmasters and SEO professionals are.
Despite this change, and in the wake of numerous protests and complaints from the community, Google has been careful not to leave a gap regarding access to archived pages. And this is where the collaboration with Internet Archive comes in, which has replaced, in part, this historical function. The removal of the cache link is thus the beginning of a new approach to providing transparency and access to historical content, but without the direct costs that Google would have had to continue to bear.
Google cache copy: how it works today with Internet Archive and Wayback Machine
With the removal of Google’s cache, the focus shifts to Internet Archive and its famous Wayback Machine as an alternative for accessing earlier versions of web pages.
In fact, in September 2024, Google began actively integrating links to this historic resource through the “About This Result” feature in its SERPs, thus offering users a new way to browse archived versions of a site.
Founded in 1996, the Internet Archive has established itself as an indispensable tool for preserving the history of the Web, allowing users to explore the evolution of millions of online pages. The Wayback Machine, an integral part of this project, allows users to view copies of websites made at specific moments in time. For users, this means having access to past versions of the same page, even after content has been changed or removed from the original site. The Wayback Machine’s role is thus functional for research, study and monitoring projects, but it proves equally useful for anyone who needs to check for changes to pages over time.
The link that Google provides within the “About This Result” feature is a step forward in ensuring persistence and transparency in accessing online information. By clicking on the three dots next to a search result, users will be able to navigate to previous versions of the page that have been archived by the Internet Archive. Although this operation requires a few more steps than the old cache system, Google has made this tool accessible precisely to compensate for the loss of its own internal cache.
This collaboration between Google and Internet Archive reflects a shift in the search engine’s priorities: maintaining continuity in access to past versions of pages-a need experienced by users and SEO professionals-but transferring this burden to a solid external alternative . In this sense,Wayback Machine proves to be one of the most important tools for anyone who needs to consult the web’s historical archive and gain broader context about the persistence of online information .
Alternatives to Google’s cache: how to save and view stored pages
With Google’s farewell to the cache, users and SEOs will no longer be able to rely on this feature to access content that is no longer available or to view older versions of a web page.
Fortunately, there are alternative systems that allow users to retrieve offline, deleted, or older version web pages.
We can no longer refer to one of the most well-known advanced search commands, namely cache: followed by the URL of the page you wish to search. With Google’s abandonment of caching, this function has also been deprecated and now the search returns a 404 error message, as in the image. Until recently, however, by entering this command directly into the Google search bar, one could attempt to access the most recent version of the page stored by Google, if available. In addition, it was also possible to use another route, namely by adding the URL of a website to “https://webcache.googleusercontent.com/search?q=cache:”

It is therefore necessary to start turning to other web page archiving tools, such as the aforementioned Internet Archive and Wayback Machine, which preserve historical snapshots of web pages and also offer the possibility of manually adding web addresses for storage. In addition to what has already been described, the “Wayback Machine” allows users to browse the history of almost any web page and view how they appeared at past dates, completely free of charge, as well as restore missing pages, read digitized books, share archived links on social media, and more (with registered accounts or even without).
It was Sullivan himself who called this system “the best alternative to the Google cache,” advocating its use.
Returning to alternatives to the Google cache, it is good to know that there are various plugins and third-party services that allow you to create personal archives of web pages, ensuring that content can be saved and accessed in the future.
Limiting then to Google’s scan verification, it is clear that all users with a verified property can use the Search Console’s URL Inspection tool to see what Google’s crawlers see when they view pages on their sites. Again, this is only part of the options originally allowed by the cache copy, but by now the die is cast and all that is left is to adapt.
How to use SEOZoom’s Monitored Pages as cache copy.
And then there is SEOZoom! We should not forget, in fact, that our software provides users with the “Monitored Pages” section that allows them to manually add specific pages or project site paths to be kept under in-depth scrutiny.
In addition to the basic functionality – analyzing page performance in detail and checking the most important data for your strategies over time – within this tool you can set it to save the page at the “current state it is in” at the time of insertion and also download the HTML version of this save. Basically, you can use SEOZoom to make a kind of cache copy of the page, also adding notes to indicate the changes you have made and later find out the outcomes and concrete results of these interventions. This is an interesting opportunity to overcome Google’s decision problem, which is certainly more oriented to the SEO aspect of page caching and clearly related to the number of projects and pages that are actually available to one’s account.
While tools such as Internet Archive are useful for accessing archived versions of websites of general interest, users who wish to save and analyze their personal or business pages in the context of an SEO strategy can rely on SEOZoom ‘s platform . The Monitored Pages feature is an advanced option for those who need not only to track changes over time, but also to save an exact copy of their web pages and check their optimization status.
This solution is ideal for those who manage sites that undergo frequent changes or those who actively participate in A/B testing and other ongoing optimization operations. Manual control and version archiving using SEOZoom is proving particularly relevant after Google decommissioned its cache, as Monitored Pages serves as a handy and immediate storage tool. Being able to track variations and establish correlations between interventions and results is essential for anyone who takes their long-term SEO strategy seriously.
Decommissioning the Google cache, the SEO and digital marketing implications
In short, the removal of Google’s cache from SERPs has an impact that is clearly reflected in SEO and digital marketing strategies .
Since we can no longer access archived versions of pages through Google, as practitioners we must adapt to new ways of working to monitor page performance and keep track of changes made over time.


For years, caching offered an immediate opportunity to check how Google “saw” a page, providing valuable data about the indexing process before any updates were recorded by the crawler. With its elimination, we need to redefine how we access past information about content, adopting more structured and advanced methods .
From a digital marketing perspective, the fallout can be just as significant. Caching used to be a lifeline to ensure that content was accessible even when a site was offline or undergoing maintenance. Now, without the ability to offer alternatives such as archived versions of a page via SERPs, it becomes essential to set up more proactive backups, making sure that any server downtime does not disrupt digital communication operations. Professionals and companies must rethink their business continuity strategies, strengthening content safeguards and improving the ability to retrieve critical information in the event of technical errors or unexpected downtime.
This change also calls for a strengthened focus on content versioning management . Early detection of changes, the use of more advanced tools for monitoring SEO performance and, above all, advance planning for any problems are now non-negotiable requirements. Practitioners must necessarily review their established habits to avoid losing their pulse on sites on a constant basis. As a function of this, it becomes crucial to adopt tools such as Internet Archive, dedicated SEO monitoring platforms (such as SEOZoom) and the heavy use of Google Search Console to analyze scans and performance in detail.
In essence, the removal of the cache represents not only the loss of a historic tool in Google’s SEO landscape, but marks the beginning of a period in which a more scientific and systematized approach to monitoring, optimizing , and preventing problems related to content indexing and visibility may emerge.
